
Unveiling the Shortcuts: How Retrieval Augmented Generation (RAG) Influences Language Model Behavior and Memory Utilization
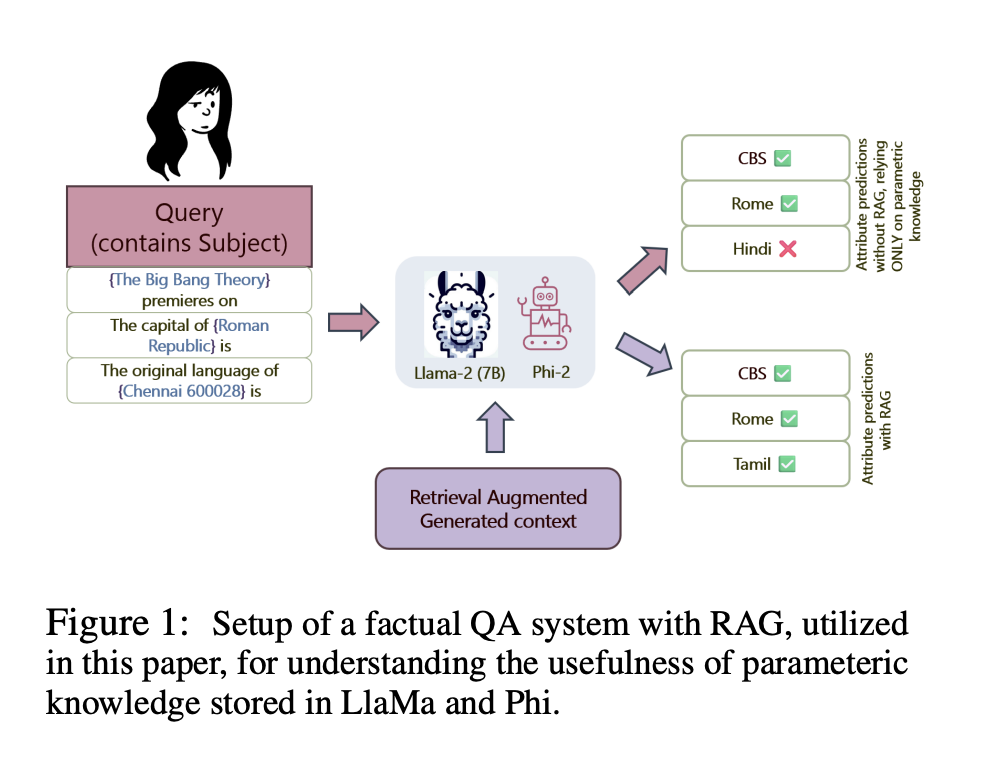
Researchers from Microsoft, the University of Massachusetts, Amherst, and the University of Maryland, College Park, address the challenge of understanding how Retrieval Augmented Generation (RAG) impacts language models’ reasoning and factual accuracy (LMs). The study focuses on whether LMs rely more on the external context provided by RAG than their parametric memory when generating responses to factual queries.
Current methods for improving the factual accuracy of LMs often involve either enhancing the internal parameters of the models or using external retrieval systems to provide additional context during inference. Techniques like ROME and MEMIT focus on editing the model’s internal parameters to update knowledge. However, there has been limited exploration into how these models balance the use of internal (parametric) knowledge and external (non-parametric) context in RAG.
The researchers propose a mechanistic examination of RAG pipelines to determine how much LMs depend on external context versus their internal memory when answering factual queries. They use two advanced LMs, LLaMa-2 and Phi-2, to conduct their analysis, employing methods like Causal Mediation Analysis, Attention Contributions, and Attention Knockouts.
The researchers utilized three key techniques to manage the inner workings of LMs under RAG:

1. Causal tracing identifies which hidden states in the model are crucial for factual predictions. By comparing a corrupted run (where part of the input is deliberately altered) with a clean run and a restoration run (where clean activations are reintroduced into the corrupted run), the researchers measure the Indirect Effect (IE) to determine the importance of specific hidden states.
2. Attention contributions look into the attention weights between the subject token and the last token in the output. This helps by analyzing how much attention each token receives to see if the model relies more on the external context provided by RAG or its internal knowledge.
3. Attention knockouts involve setting critical attention weights to negative infinity to block information flow between specific tokens. By observing the drop in prediction quality when these attention weights are knocked out, the researchers can identify which connections are essential for accurate predictions.
The results revealed that in the presence of RAG context, both LLaMa-2 and Phi-2 models showed a significant decrease in reliance on their internal parametric memory. The Average Indirect Effect of subject tokens in the query was notably lower when RAG context was present. Additionally, the last token residual stream derived more enriched information from the attribute tokens in the context rather than the subject tokens in the query. Attention Contributions and Knockouts further confirmed that the models prioritized external context over internal memory for factual predictions. However, the exact nature of how this approach works isn’t clearly understood.
In conclusion, the proposed method demonstrates that language models present a “shortcut” behavior, heavily relying on the external context provided by RAG over their internal parametric memory for factual queries. By mechanistically analyzing how LMs process and prioritize information, the researchers provide valuable insights into the interplay between parametric and non-parametric knowledge in retrieval-augmented generation. The study highlights the need for understanding these dynamics to improve model performance and reliability in practical applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.








