
Unlocking the Potential of SirLLM: Advancements in Memory Retention and Attention Mechanisms
The rapid growth of large language models (LLMs) has catalyzed the development of numerous NLP applications, such as chatbots, writing assistants, and programming aids. However, these applications often require unlimited input length and robust memory capabilities, which current LLMs lack. Extending pre-training text length is impractical, necessitating research into enabling LLMs to handle infinite input lengths while preserving memory. Recent studies focus on enhancing LLMs’ input context length, primarily through optimizing attention mechanisms. Techniques like Sliding-window attention and StreamLLM aim to extend input length but suffer from attention sink and memory loss issues, prompting exploration into filtering less important tokens to maintain longer memory spans.
Numerous studies have focused on extending the input context length of LLMs by refining the attention mechanism. Some methods like Sliding window attention, which limits each token to attend only to recent tokens, ensure stable decoding speed. Other methods like fixed Sparse Transformer and LogSparse self-attention were proposed to preserve local context information and enhance global attention. StreamLLM was introduced to achieve true infinite input length by maintaining focus on both initial and recent tokens. However, existing approaches face challenges like token preservation and forgetting issues.
Researchers from Shanghai Jiao Tong University and Wuhan University present Streaming Infinite Retentive LLM (SirLLM), a model enabling LLMs to maintain extended memory in infinite-length dialogues without requiring fine-tuning. SirLLM utilizes the Token Entropy metric and memory decay mechanism to filter key phrases, enhancing LLMs’ long-lasting and adaptable memory. Three tasks and datasets were designed to assess SirLLM’s effectiveness comprehensively: DailyDialog, Grocery Shopping, and Rock-Paper-Scissors.
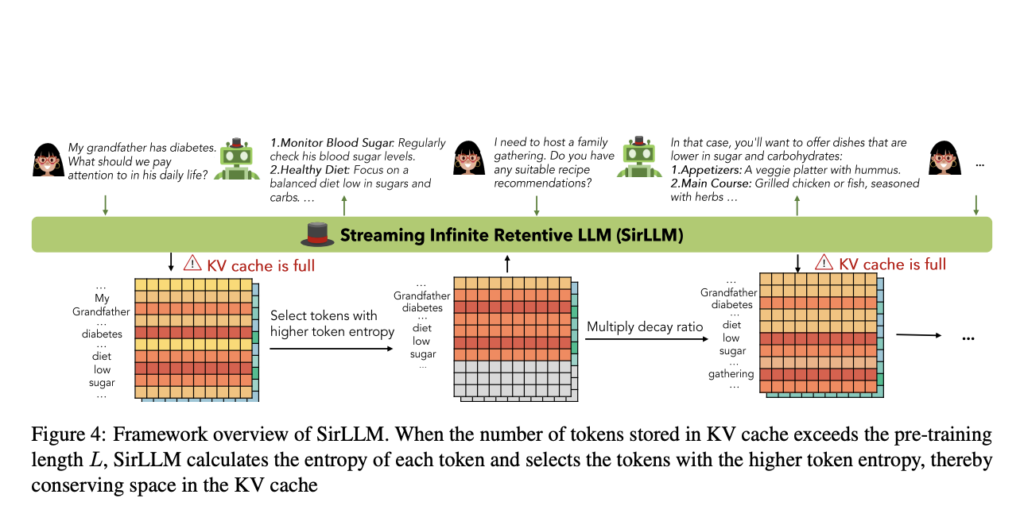
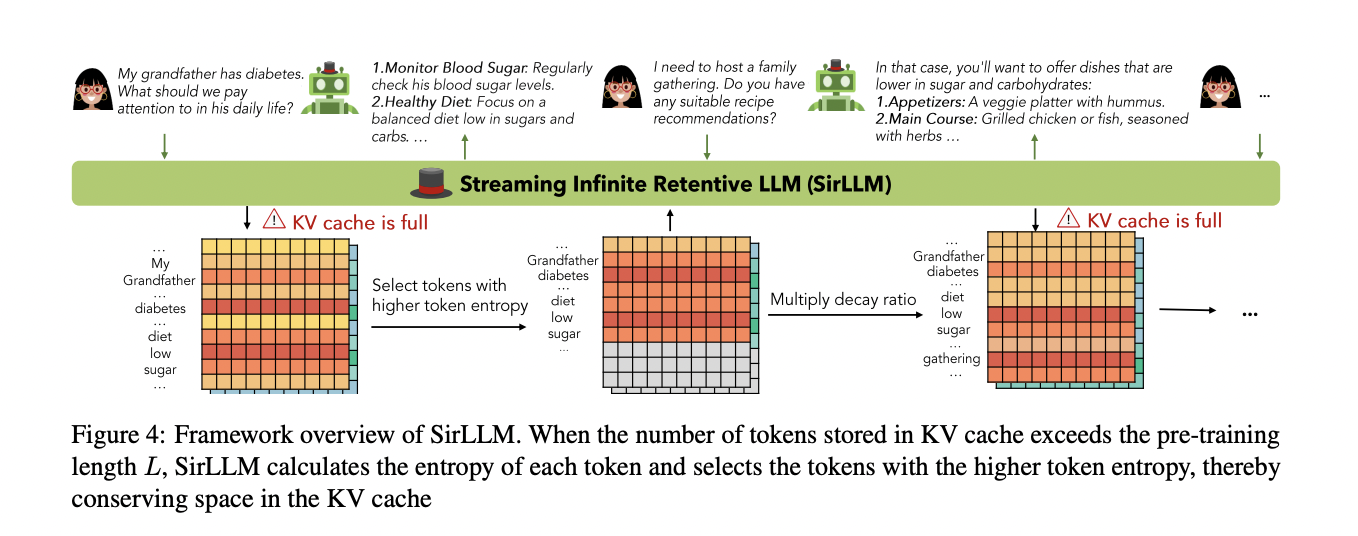
Entropy values for each token are used to enhance the model’s memory capability by selectively preserving the key-value states of only the key tokens, leading to the proposal of SirLLM. The framework overview of SirLLM involves maintaining both a key-value (KV) cache and a token entropy cache. When the number of tokens stored in the KV cache exceeds the pre-training length L, SirLLM calculates the entropy of each token and selects tokens with higher entropy, thus conserving space in the KV cache. This is achieved by selecting the top k tokens with the highest token entropy. Higher token entropy implies a lower probability of word generation, indicating key tokens with more information. SirLLM also adjusts token positions within the cache for relative distances, focusing on cache positions rather than

original text positions. However, preserving tokens solely based on entropy can lead to a rigid memory within the model, hindering adaptability. To overcome this, a decay ratio ηdecay less than 1 is proposed, allowing the model to forget older key information after each round of dialogue, thereby enhancing flexibility and user experience.
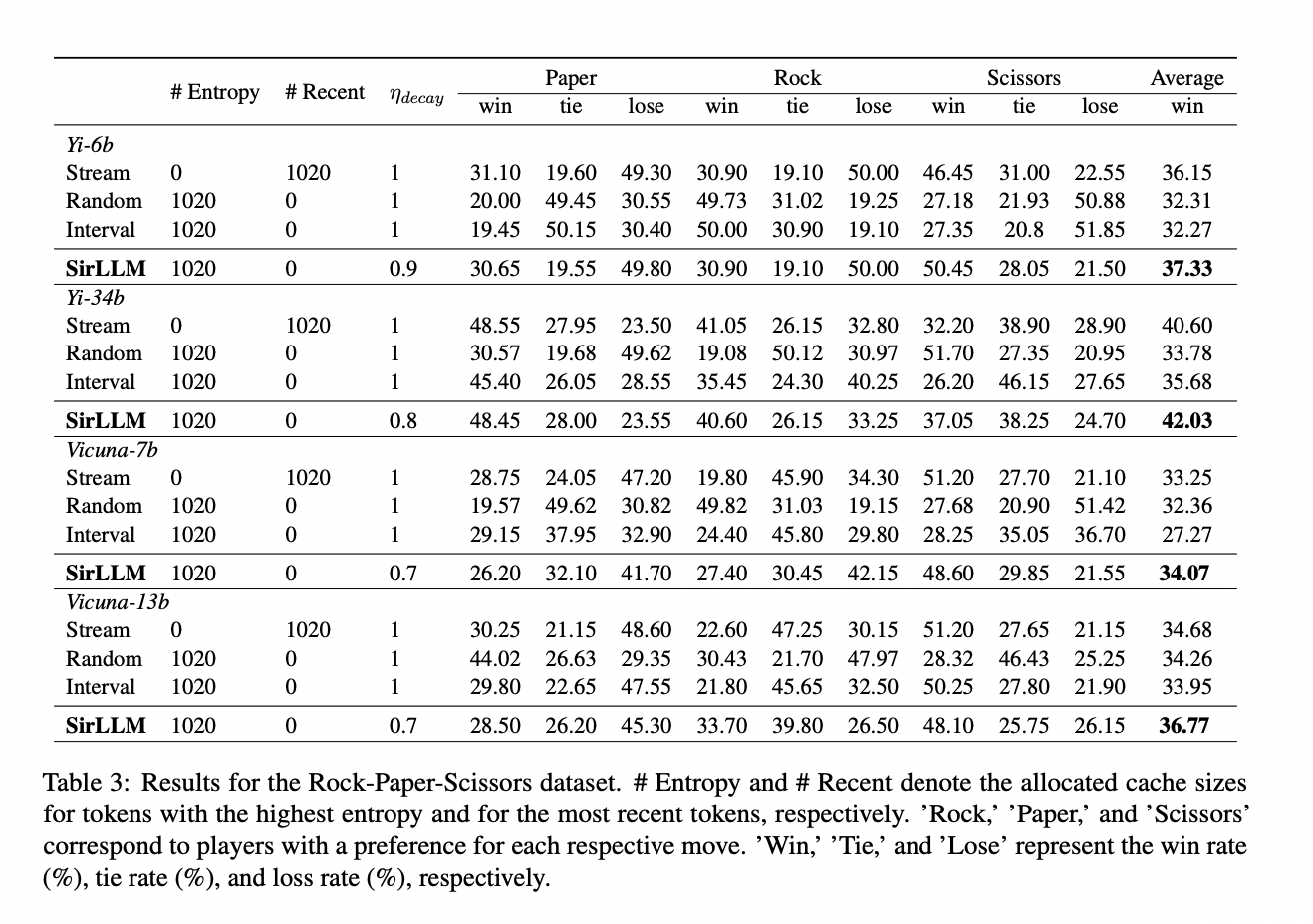
Analysis of the Rock-Paper-Scissors dataset demonstrates SirLLM’s consistent outperformance compared to the baseline StreamLLM across players with diverse throwing preferences. SirLLM exhibits a steady improvement in win rates against players of various preferences, maintaining this elevated performance consistently across all evaluated models. The integrated decay mechanism in SirLLM contributes significantly to sustaining balanced performance over multiple rounds, as evidenced by uniformly elevated win rates. This characteristic is particularly advantageous in scenarios involving prolonged interactions like extended Rock-Paper-Scissors games, highlighting SirLLM’s capacity to adapt and recall previous moves, essential for success.
Introducing SirLLM, this study addresses the critical challenges of managing infinite input lengths and memory capability. SirLLM achieves long dialogue retention without requiring model fine-tuning by selectively reinforcing the focus on pivotal information. Across three tailored tasks: DailyDialog, Grocery Shopping, and Rock-Paper-Scissors, SirLLM consistently demonstrates stable improvement over existing models, regardless of dialogue complexity or length. Experimental outcomes validate SirLLM’s robustness and versatility, positioning it as a valuable asset for future explorations and applications in natural language processing.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.










