University of South Florida Researchers Propose TeLU Activation Function for Fast and Stable Deep Learning
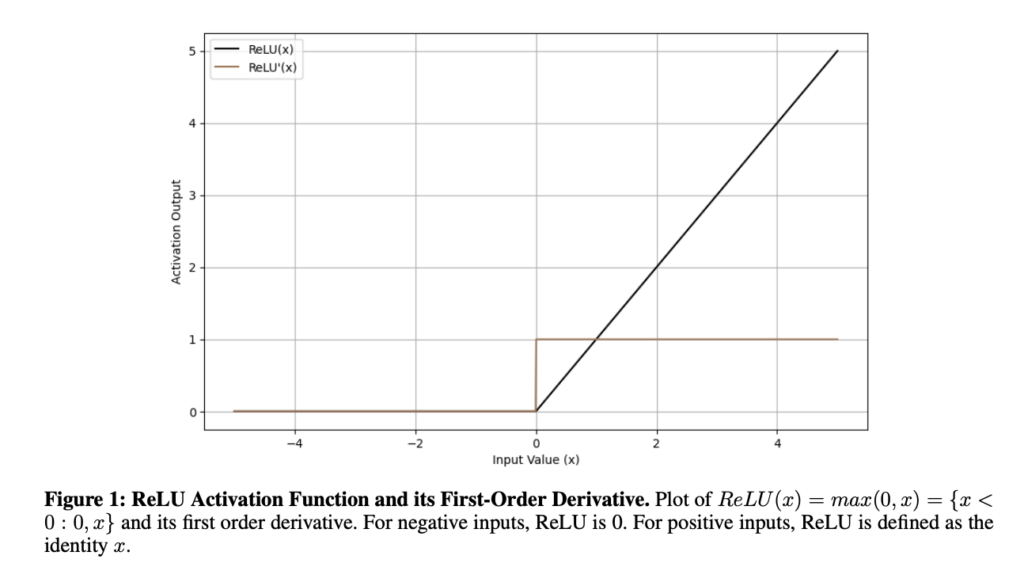
Inspired by the brain, neural networks are essential for recognizing images and processing language. These networks rely on activation functions, which enable them to learn complex patterns. However, many activation functions face challenges. Some struggle with vanishing gradients, which slows learning in deep networks, while others suffer from “dead neurons,” where certain parts of the network stop learning. Modern alternatives aim to solve these issues but often have drawbacks like inefficiency or inconsistent performance.
Currently, activation functions in neural networks face significant issues. Functions like step and sigmoid struggle with vanishing gradients, limiting their effectiveness in deep networks, and while tanh improved this slightly, which proved to have other issues. ReLU addresses some gradient problems but introduces the “dying ReLU” issue, making neurons inactive. Variants like Leaky ReLU and PReLU attempt fixes but bring inconsistencies and challenges in regularization. Advanced functions like ELU, SiLU, and GELU improve non-linearities. However, it adds complexity and biases, while newer designs like Mish and Smish showed stability only in specific cases and failed to work in overall cases.
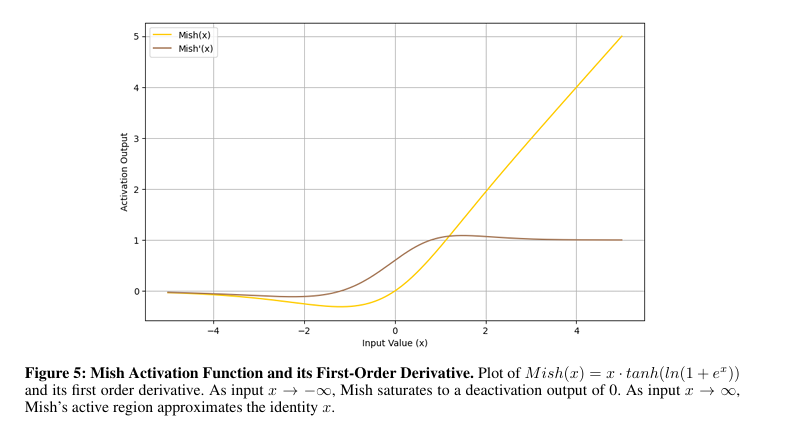
To solve these issues, researchers from the University of South Florida proposed a new activation function, TeLU(x) = x · tanh(ex), which combines the learning efficiency of ReLU with the stability and generalization capabilities of smooth functions. This function introduces smooth transitions, which means that the function output changes gradually as the input changes, near-zero-mean activations, and robust gradient dynamics to overcome some of the problems of existing activation functions. The design aims to provide consistent performance across various tasks, improve convergence, and enhance stability with better generalization in shallow and deep architectures.
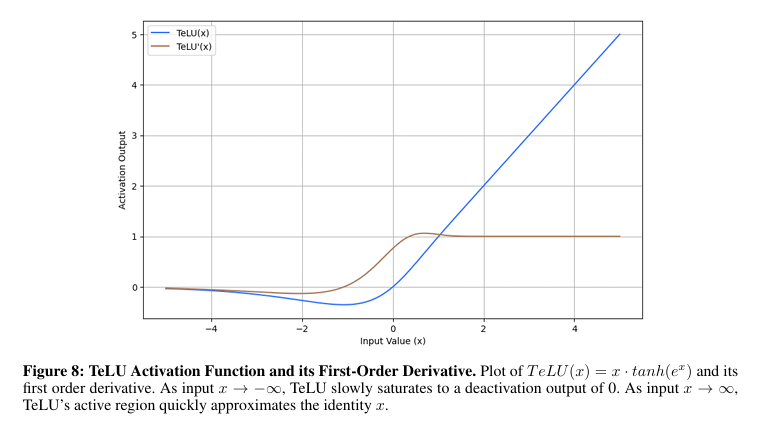
Researchers focused on enhancing neural networks while maintaining computational efficiency. Researchers aimed to converge the algorithm quickly, keep it stable during training, and make it robust to generalization over unseen data. The function exists non-polynomially and analytically; hence, it can approximate any continuous target function. The approach emphasized improving learning stability and self-regularization while minimizing numerical instability. By combining linear and non-linear properties, the framework can support efficient learning and help avoid issues such as exploding gradients.


Researchers evaluated TeLU’s performance through experiments and compared it with other activation functions. The results showed that TeLU helped to prevent the vanishing gradient problem, which is important for effectively training deep networks. It was tested on large datasets such as ImageNet and Dynamic-Pooling Transformers on Text8, showing faster convergence and better accuracy than traditional functions like ReLU. The experiments also showed that TeLU is computationally efficient and works well with ReLU-based configurations, often leading to improved results. The experiments confirmed that TeLU is stable and performs better across various neural network architectures and training methods.

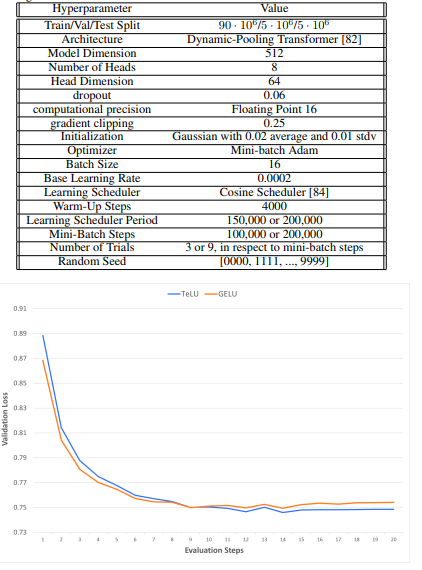
In the end, the proposed activation function by the researchers handled key challenges of existing activation functions by preventing the vanishing gradient problem, enhancing computational efficiency, and showing better performance across diverse datasets and architectures. Its successful application on benchmarks like ImageNet, Text8, and Penn Treebank, showing faster convergence, accuracy improvements, and stability in deep learning models, can position TeLU as a promising tool for deep neural networks. Also, TeLU’s performance can serve as a baseline for future research, which can inspire further development of activation functions to achieve even greater efficiency and reliability in machine learning advancements.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.