Understanding the Hidden Layers in Large Language Models LLMs
Hebrew University Researchers addressed the challenge of understanding how information flows through different layers of decoder-based large language models (LLMs). Specifically, it investigates whether the hidden states of previous tokens in higher layers are as crucial as believed. Current LLMs, such as transformer-based models, use the attention mechanism to process tokens by attending to all previous tokens in every layer. While each transformer layer applies this attention uniformly, prior research indicates that different layers capture different types of information. The study builds on the idea that not all layers may equally rely on the hidden states of previous tokens, especially in higher layers.
The research team hypothesized that while lower layers focus on aggregating information from previous tokens, higher layers may rely less on this information. They propose various manipulations in the hidden states of previous tokens in different layers of the model. These include replacing hidden states with random vectors, freezing hidden states at specific layers, and swapping the hidden states of one token with another from a different prompt. They conduct experiments on four open-source LLMs (Llama2-7B, Mistral-7B, Yi-6B, and Llemma-7B) and four tasks, including question answering and summarization, to evaluate the impact of these manipulations on model performance.
One technique involves introducing noise by replacing hidden states with random vectors, which allows researchers to evaluate whether the content of these hidden states still matters at certain layers. The second method, freezing, locks the hidden states at a particular layer and reuses them for the subsequent layers, reducing the computational load.
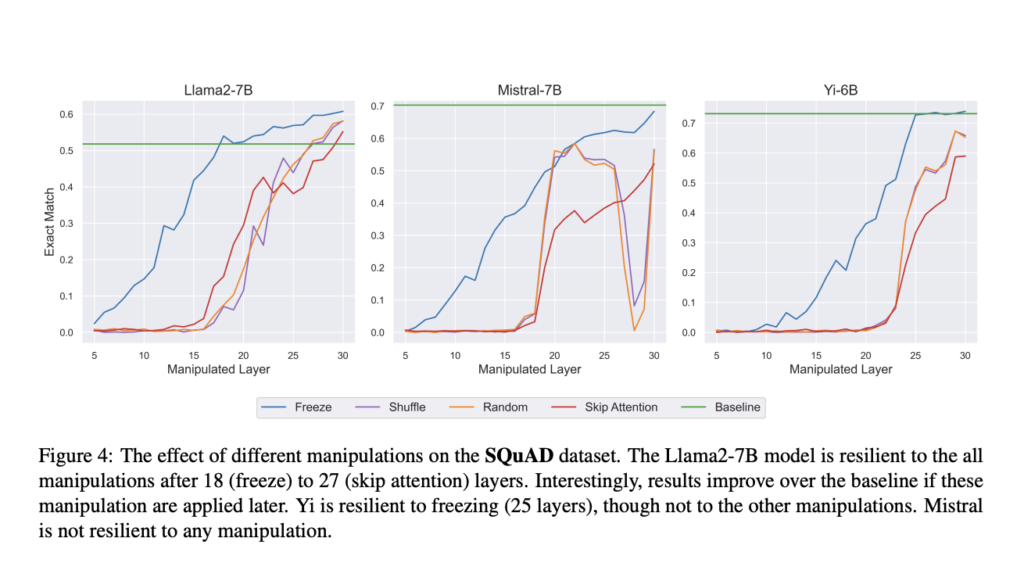
The researchers found that when these manipulations were applied to the top 30-50% of the model, performance across multiple tasks experienced little to no drop, suggesting that the top layers rely less on the hidden representations of previous tokens. For example, when freezing up to 50% of the layers, the models retained performance similar to that of the baseline. Additionally, swapping hidden states from different prompts further confirmed this observation; the model ignored changes made in the top layers, while changes in lower layers significantly altered the output. The experiments were conducted to understand whether attention was needed in the higher layers of the model by skipping the attention block in those layers. This test demonstrated that skipping attention in the upper layers had minimal impact on tasks like summarization and question answering, while doing so in lower layers led to severe performance degradation.

In conclusion, the study reveals a two-phase process in transformer-based LLMs: the early layers gather information from previous tokens, while the higher layers primarily process that information internally. The findings suggest that higher layers are less dependent on the detailed representation of previous tokens, offering potential optimizations, such as skipping attention in these layers to reduce computational costs. Overall, the paper dives deep into the hierarchical nature of information processing in LLMs and leads to more informed and efficient model designs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
⏩ ⏩ FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.