This AI Paper Proposes TALE: An AI Framework that Reduces Token Redundancy in Chain-of-Thought (CoT) Reasoning by Incorporating Token Budget Awareness
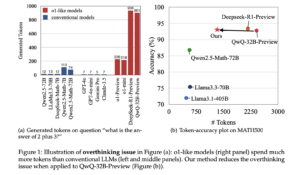
Large Language Models (LLMs) have shown significant potential in reasoning tasks, using methods like Chain-of-Thought (CoT) to break down complex problems into manageable steps. However, this capability comes with challenges. CoT prompts often increase token usage, leading to higher computational costs and energy consumption. This inefficiency is a concern for applications that require both precision and resource efficiency. Current LLMs tend to generate unnecessarily lengthy outputs, which do not always translate into better accuracy but incur additional costs. The key challenge is finding a balance between reasoning performance and resource efficiency.
Researchers from Nanjing University, Rutgers University, and UMass Amherst have introduced a Token-Budget-Aware LLM Reasoning Framework. This framework dynamically estimates token budgets based on the complexity of a reasoning task and uses these estimates to guide the process. Known as TALE (Token-Budget-Aware LLM rEasoning), the approach seeks to reduce token usage without compromising the accuracy of responses. By integrating a token budget into CoT prompts, TALE provides a practical solution for enhancing cost-efficiency in LLMs while maintaining their performance.
Technical Details and Benefits
TALE operates in two main phases: budget estimation and token-budget-aware reasoning. Initially, it estimates an appropriate token budget for a problem using methods such as zero-shot prediction or regression-based estimators. This budget is then embedded in the prompt to encourage the LLM to generate concise yet accurate responses.
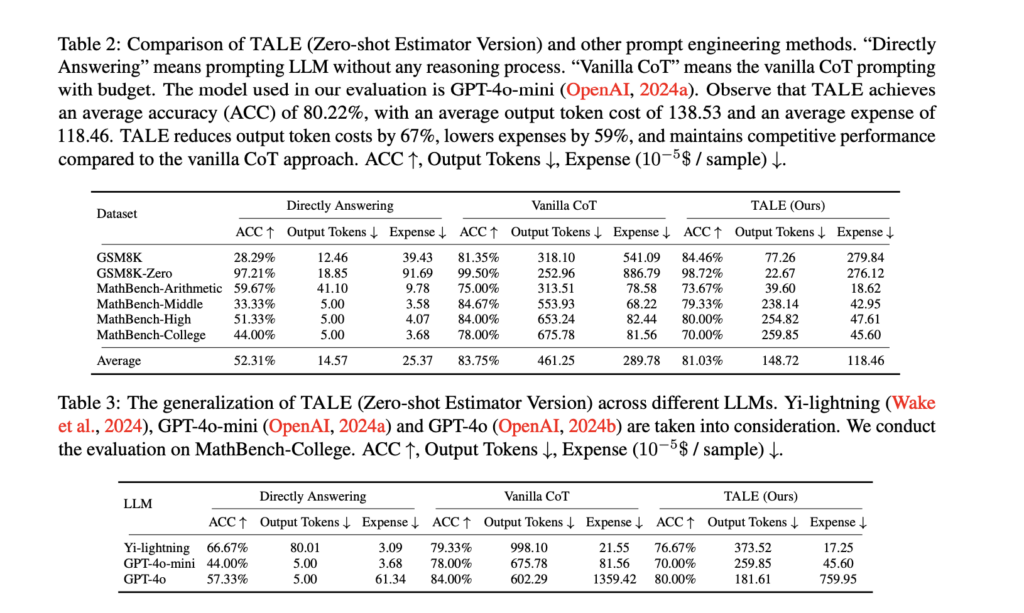
A key innovation in TALE is the concept of “Token Elasticity,” which identifies an optimal range of token budgets that minimizes token usage while preserving accuracy. Using iterative search techniques like binary search, TALE determines the optimal budget for various tasks and LLM architectures. On average, the framework achieves a 68.64% reduction in token usage with less than a 5% decrease in accuracy, making it a practical and adaptable approach for token efficiency.

Results and Insights
Experiments demonstrate TALE’s effectiveness across benchmarks like GSM8K and MathBench. For instance, on the GSM8K dataset, TALE achieved 84.46% accuracy, surpassing the Vanilla CoT method while reducing token costs from 318.10 to 77.26 on average. On GSM8K-Zero, it reduced token costs by 91%, maintaining an accuracy of 98.72%.
TALE also generalizes well across different LLMs, such as GPT-4o-mini and Yi-lightning. When applied to the MathBench-College dataset, TALE reduced token costs by up to 70% while maintaining competitive accuracy. Additionally, the framework significantly lowers operational expenses, cutting costs by 59% on average compared to Vanilla CoT. These results highlight TALE’s ability to enhance efficiency without sacrificing performance, making it suitable for a variety of applications.

Conclusion
The Token-Budget-Aware LLM Reasoning Framework addresses the inefficiency of token usage in reasoning tasks. By dynamically estimating and applying token budgets, TALE strikes a balance between accuracy and cost-effectiveness. This approach reduces computational expenses and broadens the accessibility of advanced LLM capabilities. As AI continues to evolve, frameworks like TALE offer a pathway to more efficient and sustainable use of LLMs in both academic and industrial contexts.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.