Solving the ‘Lost-in-the-Middle’ Problem in Large Language Models: A Breakthrough in Attention Calibration
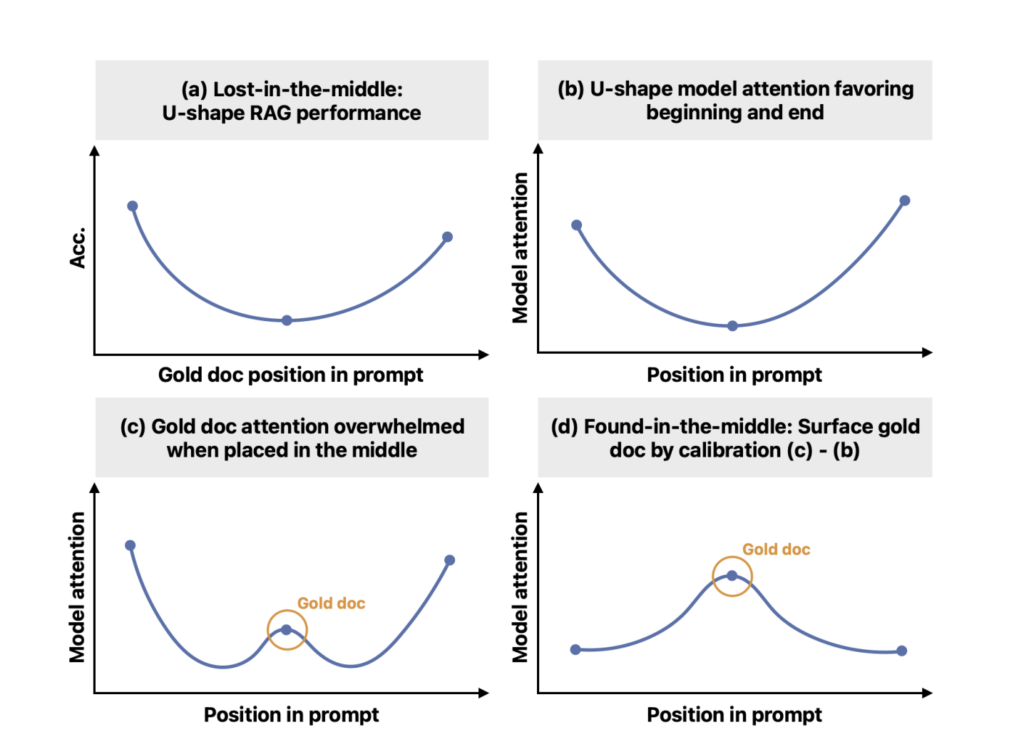
Despite the significant advancement in large language models (LLMs), LLMs often need help with long contexts, especially where information is spread across the complete text. LLMs can now handle long stretches of text as input, but they still face the “lost in the middle” problem. The ability of LLMs to accurately find and use information within that context weakens as the relevant information gets further away from the beginning or end. In other words, they tend to focus on the information at the beginning and end, neglecting what’s sandwiched in between.
Researchers from the University of Washington, MIT, Google Cloud AI Research, and Google collaborated to address the “lost-in-the-middle” issue. Despite being trained to handle large input contexts, LLMs exhibit an inherent attention bias that results in higher attention to tokens at the beginning and end of the input. This leads to reduced accuracy when critical information is situated in the middle. The study aims to mitigate the positional bias by allowing the model to attend to contexts based on their relevance, regardless of their position within the input sequence.
Current methods to tackle the lost-in-the-middle problem often involve re-ranking the relevance of documents and repositioning the most pertinent ones at the beginning or end of the input sequence. However, these methods usually require additional supervision or fine-tuning and do not fundamentally address the LLMs’ ability to utilize mid-sequence information effectively. To overcome this limitation, the researchers propose a novel calibration mechanism called “found-in-the-middle.”
The researchers first establish that the lost-in-the-middle issue is linked to a U-shaped attention bias. The inherent bias persists even when the order of documents is randomized. To verify their hypothesis, the authors intervene by adjusting the attention distribution to reflect relevance rather than position. They quantify this positional bias by measuring changes in attention as they vary the position of a fixed context within the input prompt.

The proposed “found-in-the-middle” mechanism disentangles positional bias from the attention scores, enabling a more accurate reflection of the documents’ relevance. This calibration involves estimating the bias and adjusting attention scores accordingly. Experiments demonstrate that the calibrated attention significantly improves the model’s ability to locate relevant information within long contexts, leading to better performance in retrieval-augmented generation (RAG) tasks.
The researchers operationalize this calibration mechanism to improve overall RAG performance. The attention calibration method consistently outperforms uncalibrated models across various tasks and models, including those with different context window lengths. The approach yields improvements of up to 15 percentage points on the NaturalQuestions dataset. Additionally, combining attention calibration with existing reordering methods further enhances model performance, demonstrating the effectiveness and complementarity of the proposed solution.
In conclusion, the proposed mechanism effectively identifies and addresses the lost-in-the-middle phenomenon by linking it to intrinsic positional attention bias in LLMs. The found-in-the-middle mechanism successfully mitigates this bias, enabling the models to attend to relevant contexts more faithfully and significantly improving performance in long-context utilization tasks. This advancement opens new ways for enhancing LLM attention mechanisms and their application in various user-facing applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
🚀 Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.