
Self-play muTuAl Reasoning (rStar): A Novel AI Approach that Boosts Small Language Models SLMs’ Reasoning Capability during Inference without Fine-Tuning
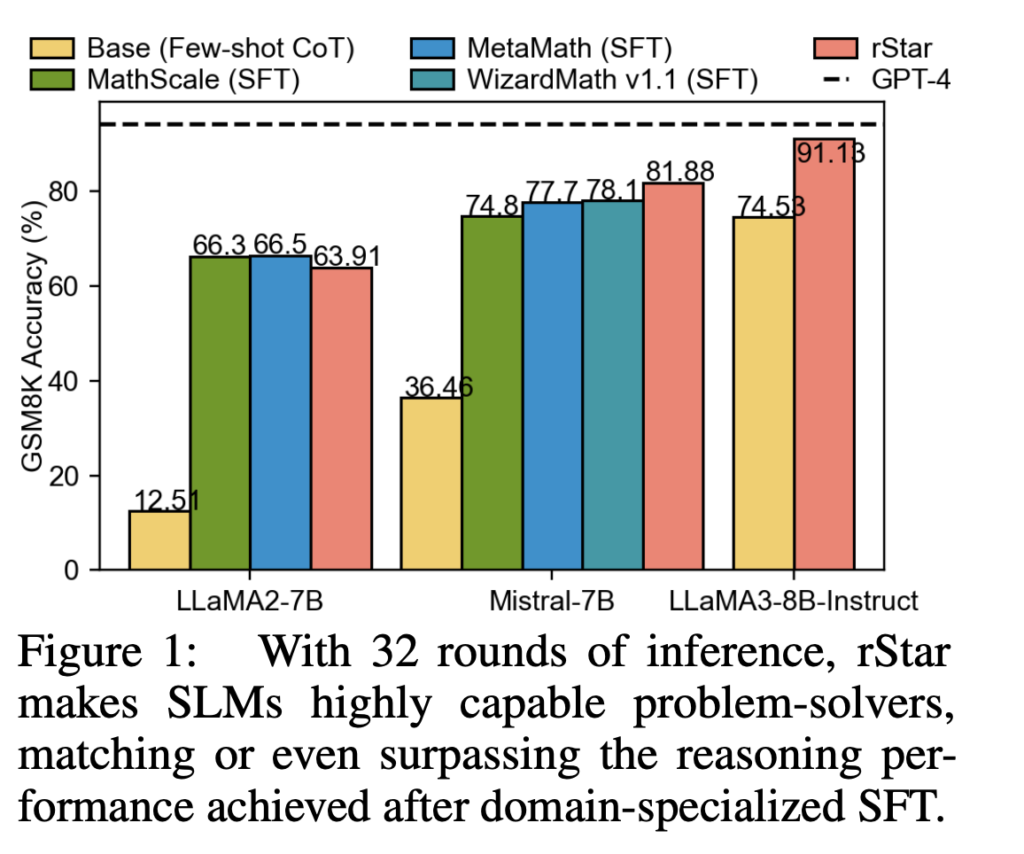
Large language models (LLMs) have made significant strides in various applications, but they continue to face substantial challenges in complex reasoning tasks. For instance, even advanced models like Mistral-7B can only achieve 36.5% accuracy on the GSM8K dataset, despite employing techniques such as Chain-of-Thought (CoT). While fine-tuning has shown promise in improving reasoning capabilities, most LLMs rely on data distilled or synthesized by superior models like GPT-4. This dependency on more advanced models has led researchers to explore alternative approaches to enhance reasoning without relying on a superior teacher LLM. However, this endeavour presents its challenges, particularly for smaller language models (SLMs), which need help with effective solution space exploration and quality assessment of reasoning steps.
Researchers have made various attempts to enhance the reasoning capabilities of language models. Prompting-based methods, such as Chain-of-Thought, focus on designing instructions and pipelines to improve performance during inference. These approaches include planning, problem decomposition, abstraction, and programming techniques. Also, self-improvement methods have gained traction, with fine-tuning approaches utilizing pre-trained LLMs to synthesise data and enhance performance progressively. Advanced prompting techniques like self-verification and RAP aim to improve performance through iterative self-exploration. Sampling diverse reasoning paths has shown promise in mathematical reasoning tasks, with methods like Self-Consistency and tree-search approaches breaking down tasks into simpler steps. For answer verification, majority voting is widely used, while some researchers have explored training value or reward models, though these require additional annotations and risk overfitting.
Researchers from Microsoft Research Asia and Harvard University introduced the Self-play muTuAl Reasoning (rStar) approach, a robust solution to enhance SLMs reasoning capabilities during inference, without relying on fine-tuning or superior models. rStar tackles the challenges faced by SLMs through a unique self-play mutual generation-discrimination process. This method employs a conventional Monte Carlo Tree Search (MCTS) for self-generating reasoning steps but expands the set of reasoning actions to simulate human reasoning behaviors. These actions include decomposing problems, searching for specific reasoning steps, proposing new sub-questions, and rephrasing given questions. To guide the exploration of generated reasoning trajectories effectively, rStar introduces a discrimination process called mutual consistency, which employs a second SLM as a discriminator to provide unsupervised feedback on candidate reasoning trajectories.
The rStar approach employs a unique architecture to enhance SLMs reasoning capabilities. At its core, rStar uses an MCTS algorithm to augment the target SLM for self-generating multi-step reasoning solutions. The method introduces a rich set of five human-like reasoning actions, including proposing one-step thoughts, generating remaining thought steps, proposing and answering sub-questions, re-answering sub-questions, and rephrasing questions. This diverse action space allows for thorough exploration across various reasoning tasks.

rStar implements a carefully designed reward function that evaluates each action’s value without relying on self-rewarding techniques or external supervision. The MCTS rollout process uses the Upper Confidence Bounds applied to Trees (UCT) algorithm to balance exploration and exploitation during tree expansion. To verify the generated reasoning trajectories, rStar introduces a second SLM as a discriminator, employing a mutual consistency approach. This process involves masking part of a candidate trajectory and asking the discriminator SLM to complete it, then comparing the results for consistency.
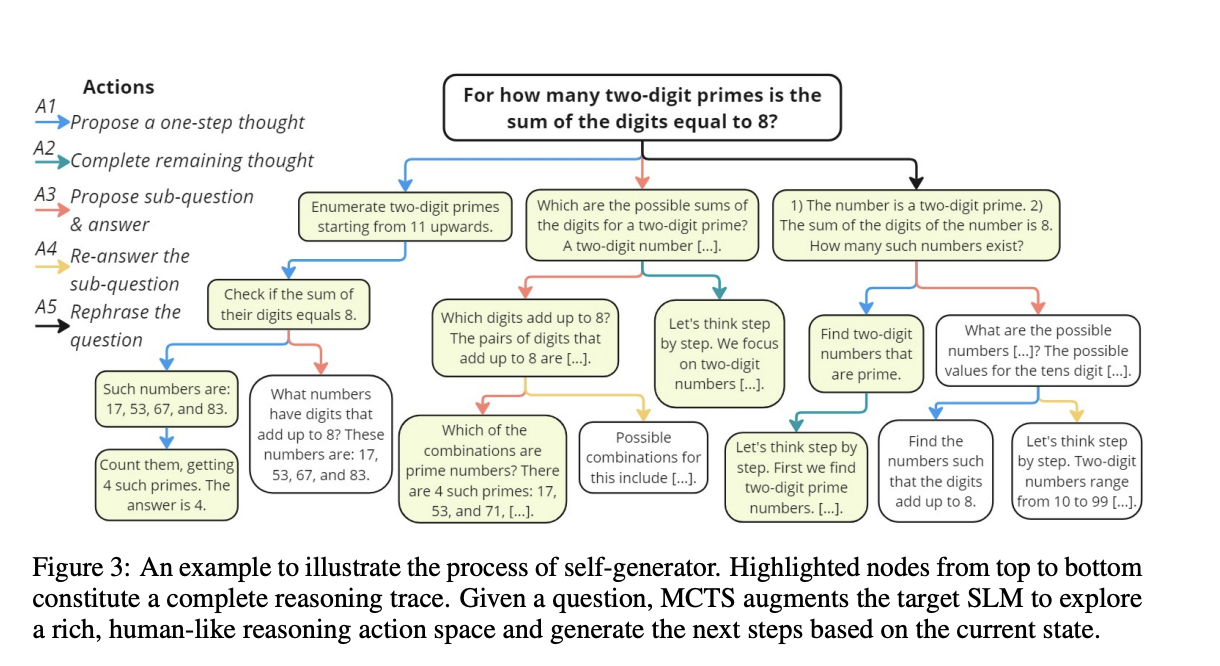
The results demonstrate the effectiveness of rStar across various reasoning benchmarks and language models:
1. Performance on diverse reasoning tasks:
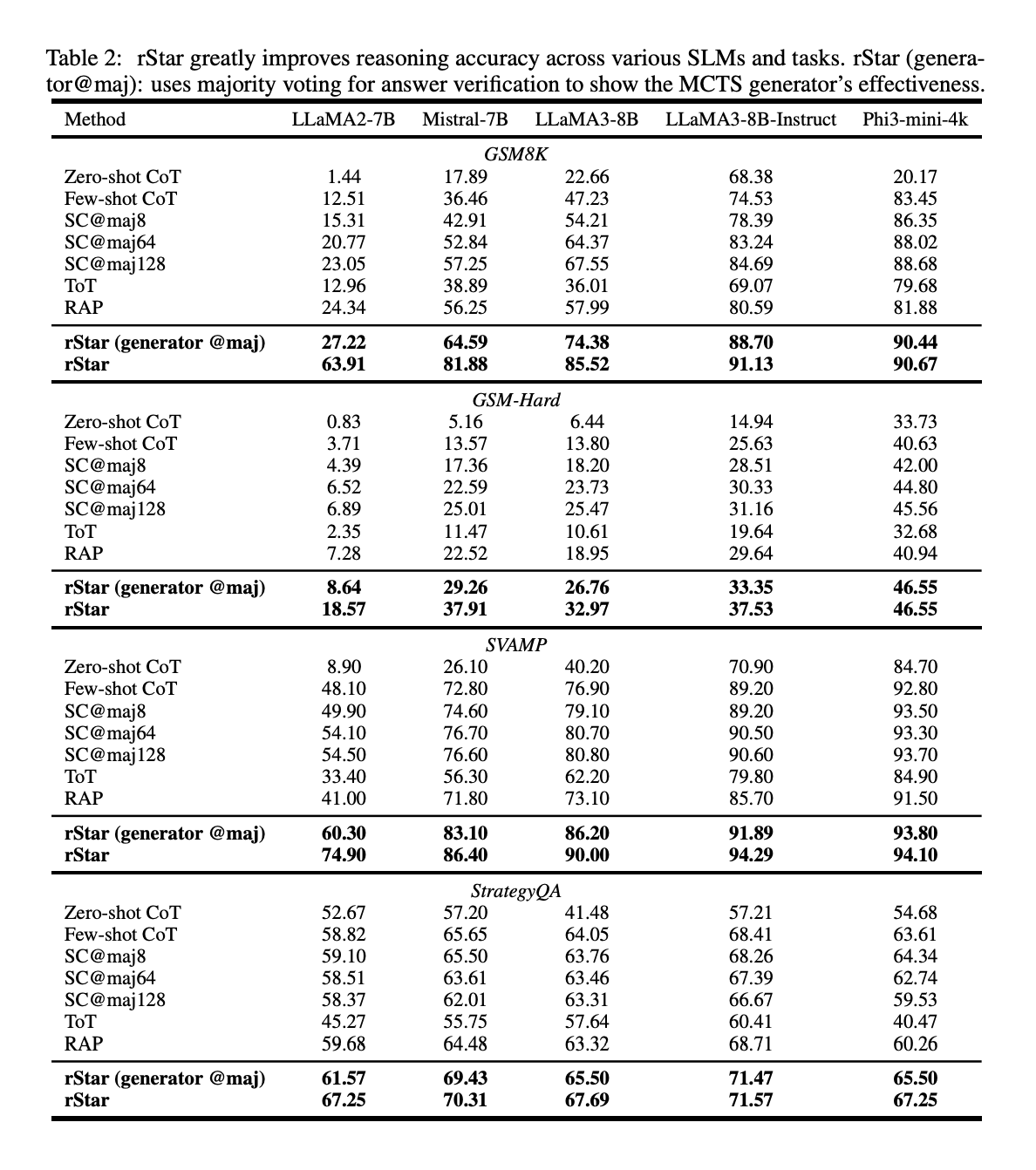
rStar significantly improved SLMs’ problem-solving abilities. For example, LLaMA2-7B’s accuracy on GSM8K increased from 12.51% with few-shot CoT to 63.91% with rStar, nearly matching fine-tuned performance.
rStar consistently improved reasoning accuracy across different SLMs and tasks to state-of-the-art levels, outperforming other baseline approaches.
Even without the discriminator, rStar’s generator outperformed existing multi-round inference baselines like RAP, ToT, and Self-Consistency on GSM8K.
2. Efficiency:
rStar showed significant improvements in reasoning accuracy with just 2 rollouts on the GSM8K dataset.
3. Performance on challenging mathematical datasets:
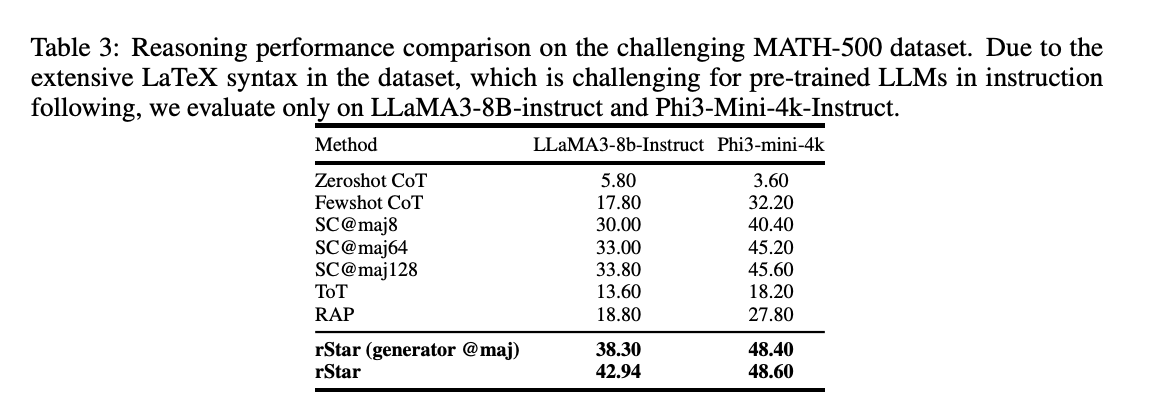
On GSM-Hard and MATH-500, rStar improved SLMs’ reasoning accuracy significantly, with improvements of up to 12.9% and 9.14% respectively compared to state-of-the-art baselines.
4. Ablation studies:
The MCTS generator in rStar outperformed other approaches like RAP and Self-Consistency across different models and tasks.
rStar’s discriminator consistently outperformed other verification methods, including majority voting and self-verification, across different generators.
5. Model comparisons:
Different models were tested as discriminators, with GPT-4 achieving the highest accuracy (92.57%) on GSM8K, followed by Phi3-Mini-Instruct (91.13%).
These results highlight rStar’s effectiveness in enhancing SLMs’ reasoning capabilities across various tasks and models, outperforming existing methods in both accuracy and efficiency.
The rStar approach introduces a robust generator-discriminator self-play method that significantly enhances the reasoning capabilities of SLMs during inference. This research reveals that SLMs like LLaMA2-7B possess strong inherent reasoning abilities even before domain-specific supervised fine-tuning. rStar demonstrates state-of-the-art performance across five different SLMs and five diverse reasoning tasks, substantially outperforming existing multi-round prompting and self-improvement techniques. The extensive ablation studies and analysis conducted in this research contribute valuable insights to the field, paving the way for more advanced self-improved reasoning techniques in SLMs. These findings highlight the potential of rStar in unlocking the latent reasoning capabilities of language models without the need for extensive fine-tuning or reliance on larger models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.










