
Revolutionizing Recurrent Neural Networks RNNs: How Test-Time Training TTT Layers Outperform Transformers
Self-attention mechanisms can capture associations across entire sequences, making them excellent at processing extended contexts. However, they have a high computational cost, namely quadratic complexity, which implies that as the sequence length increases, the amount of time and memory needed increases. Recurrent Neural Networks (RNNs), on the other hand, have linear complexity, which increases their computational efficiency. However, due to the constraints placed on their hidden state, which needs to contain all of the data in a fixed-size representation, RNNs perform poorly in lengthy settings.
To overcome these limitations, a team of researchers from Stanford University, UC San Diego, UC Berkeley, and Meta AI has suggested a unique class of sequence modeling layers that combines a more expressive hidden state with the linear complexity of RNNs. The main concept is to employ a self-supervised learning step as the update rule and turn the concealed state into a machine learning model. This implies that the hidden state is updated by efficiently training on the input sequence, even during the test phase. These levels are referred to as Test-Time Training (TTT) layers.
TTT-Linear and TTT-MLP are the two distinct varieties of TTT layers that have been introduced. Whereas the hidden state of TTT-MLP is a two-layer Multilayer Perceptron (MLP), the hidden state of TTT-Linear is a linear model. The team has tested the performance of these TTT layers against a robust Transformer model and Mamba, a contemporary RNN, evaluating them over models with parameters ranging from 125 million to 1.3 billion.
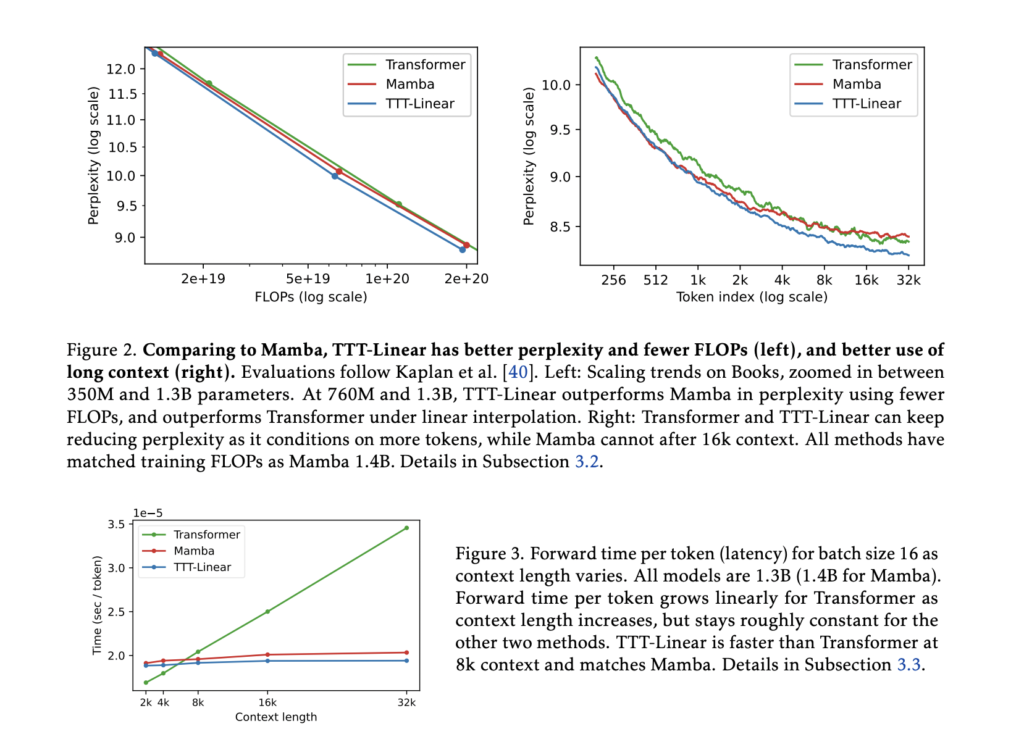
According to the evaluations, TTT-Linear and TTT-MLP both perform on par with or better than the baselines. Similar to the Transformer, TTT layers keep getting smaller as they condition on additional tokens. Perplexity is a metric that assesses how well a model predicts a sequence. This is a big benefit because it shows that TTT layers employ extended contexts well, whereas Mamba stops improving at 16,000 tokens.

After some preliminary optimizations, TTT-Linear matched Mamba in wall-clock time, which is a measure of the real amount of time that elapses while processing and beat the Transformer in speed for sequences up to 8,000 tokens. Though it has more potential for managing lengthy contexts, TTT-MLP still has issues with memory input/output operations.
The team has summarized their primary contributions as follows:
A unique class of sequence modeling layers has been introduced, called Test-Time Training (TTT) layers, in which a model updated via self-supervised learning serves as the hidden state. This view presents a new avenue for sequence modeling research by integrating a training loop into a layer’s forward pass.
A straightforward instantiation of TTT layers called TTT-Linear has been introduced, and the team has shown that it performs better in evaluations with model sizes ranging from 125 million to 1.3 billion parameters than both Transformers and Mamba, suggesting that TTT layers have the ability to improve sequence models’ performance.
The team has also created mini-batch TTT and the dual form to increase the hardware efficiency of TTT layers, which makes TTT-Linear a useful building block for large language models. These optimizations make the integration of TTT layers into practical applications more feasible.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.









