
pEBR: A Novel Probabilistic Embedding based Retrieval Model to Address the Challenges of Insufficient Retrieval for Head Queries and Irrelevant Retrieval for Tail Queries
Creating a common semantic space where queries and items can be represented as dense vectors is the main goal of embedding-based retrieval. Instead of depending on precise keyword matches, this method enables effective matching based on semantic similarities. Semantically related things are positioned closer to one another in this common area since searches and items are embedded in this manner. Approximate Nearest Neighbour (ANN) methods, which greatly improve the speed and effectiveness of locating pertinent objects within big datasets, are made possible by this.
Retrieval systems are made to retrieve a certain amount of items per query in the majority of industrial applications. However, this consistent retrieval strategy has limitations. Popular or head inquiries, like those pertaining to well-known products, could, for instance, need a wider range of results in order to fully capture the range of pertinent objects. The low recall could arise from a set cutoff for these searches, which would leave out some pertinent items. On the other hand, the system could return too many irrelevant results for more focused or tail queries, which usually contain fewer pertinent things, decreasing precision. The common use of frequentist techniques for creating loss functions, which frequently fail to take into consideration the variation among various query types, is partly to blame for this difficulty.
To overcome these limitations, a team of researchers has introduced Probabilistic Embedding-Based Retrieval (pEBR), a probabilistic approach that replaces the frequentist approach. Instead of handling every question in the same way, pEBR dynamically modifies the retrieval procedure according to the distribution of pertinent items that underlie each inquiry. In particular, pEBR uses a probabilistic cumulative distribution function (CDF) to determine a dynamic cosine similarity threshold customized for every query. The retrieval system is able to define adaptive thresholds that better meet the unique requirements of each query by modeling the likelihood of relevant items for each query. This enables the retrieval system to capture more relevant things for head queries and filter out irrelevant ones for tail queries.
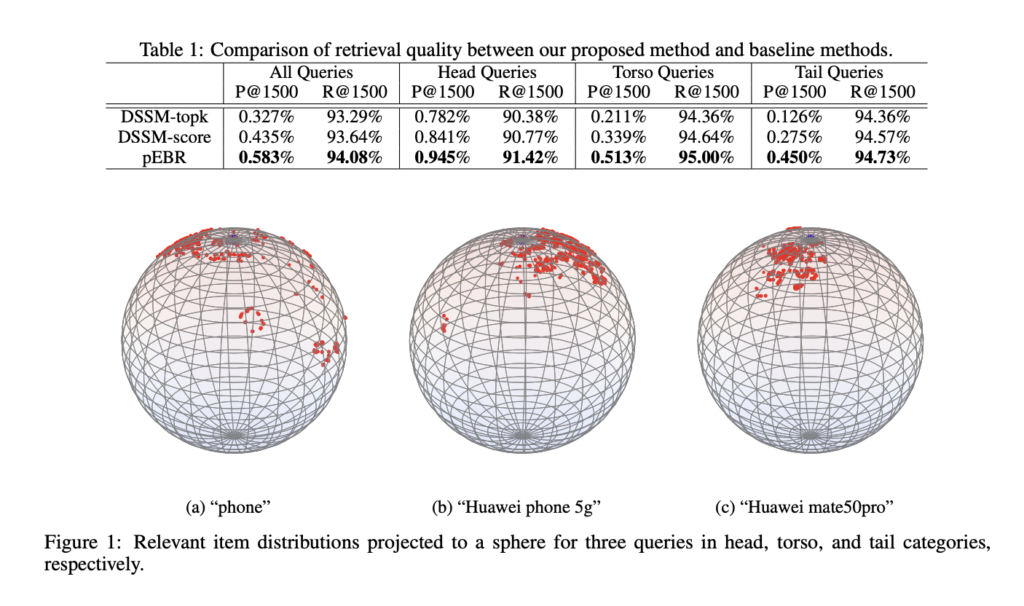
The team has shared that according to experimental findings, this probabilistic method enhances recall, i.e., the comprehensiveness of results, and precision, ie.., the relevance of results. Furthermore, ablation tests, which methodically eliminate model components to assess their effects, have demonstrated that pEBR’s effectiveness is largely dependent on its capacity to adaptively differentiate between head and tail queries. pEBR has overcome the drawbacks of fixed cutoffs by capturing the distinct distribution of pertinent items for every query, offering a more accurate and adaptable retrieval experience for a variety of query patterns.

The team has summarized their primary contributions as follows.
The two-tower paradigm, in which items and questions are represented in the same semantic space, has been introduced as the conventional method for embedding-based retrieval.
Popular point-wise and pair-wise loss functions in retrieval systems have been characterized as fundamental techniques.
The study has suggested loss functions based on contrastive and maximum likelihood estimation to improve retrieval performance.
The usefulness of the suggested approach has been demonstrated by experiments, which revealed notable gains in retrieval accuracy.
Ablation research has examined the model’s constituent parts to understand how each component affects overall performance.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.









