
Optimizing Memory for Large-Scale NLP Models: A Look at MINI-SEQUENCE TRANSFORMER
The evolution of Transformer models has revolutionized natural language processing (NLP) by significantly advancing model performance and capabilities. However, this rapid development has introduced substantial challenges, particularly regarding the memory requirements for training these large-scale models. As Transformer models grow in size and complexity, managing the memory demands becomes increasingly critical. The paper addresses this pressing issue by proposing a novel methodology to optimize memory usage without compromising the performance of long-sequence training.
Traditional approaches, such as multi-query attention and grouped query attention (GQA), have significantly reduced memory usage during inference by optimizing the key-value cache size. These techniques have been successfully implemented in large-scale models like PaLM and LLaMA. However, the ongoing enhancements in model architecture, such as the increased vocabulary size and intermediate layers in Llama3, continue exacerbating memory challenges during training.
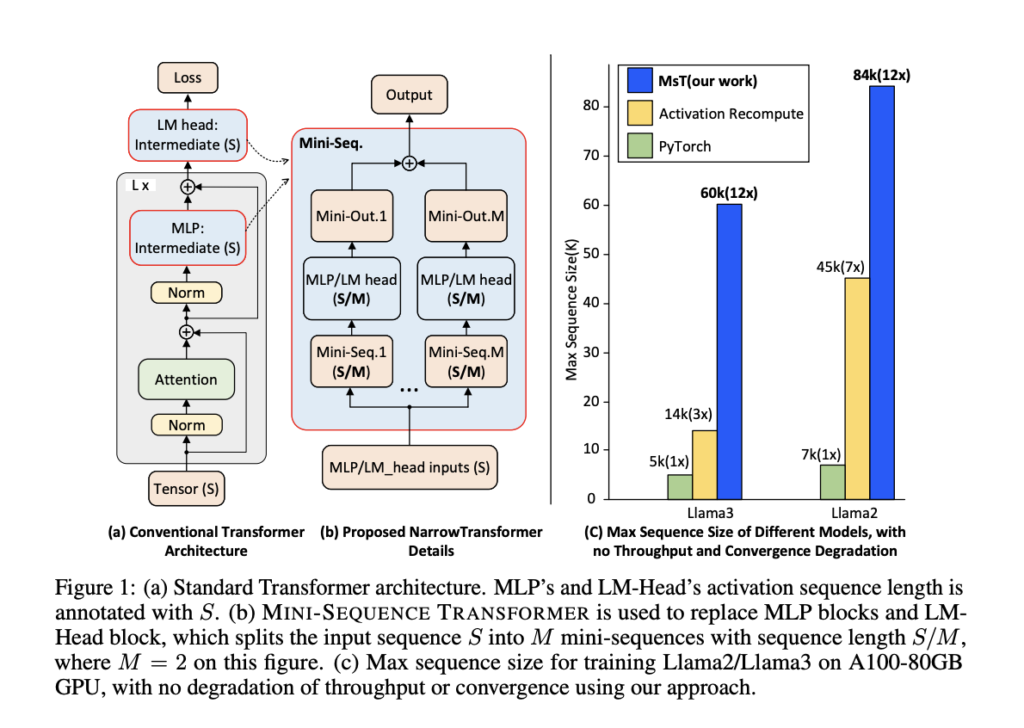
A team of researchers from Caltech and CMU propose the MINI-SEQUENCE TRANSFORMER (MST) to address these challenges. MST introduces a method that partitions input sequences and processes them iteratively as mini-sequences. This approach significantly reduces intermediate memory usage by integrating activation recomputation, a technique that involves recalculating the activations of certain layers during the backward pass, which saves memory in both forward and backward passes. MST is designed to be implementation-agnostic and requires minimal code modifications to integrate with existing training frameworks. This method maintains high efficiency and accuracy even when dealing with extremely long sequences.
The MST methodology reduces memory usage by partitioning input sequences into smaller mini-sequences. During the training of models like Llama3-8B, the memory allocated for activations in the forward pass is substantial, and similar challenges arise during the backward pass. MST mitigates this by processing smaller chunks iteratively, thereby reducing the memory footprint. This approach also involves optimizing the memory allocated for gradients and optimizer states, further enhancing the overall efficiency of the training process.

In addition to the basic MST, the researchers extend this method to a distributed setting. By combining MST with DeepSpeed-Ulysses, the input tensor of each Transformer layer is divided along the sequence dimension, allowing for parallel computation across multiple GPUs—this segmentation, along with activation recomputation, results in a substantial reduction in activation memory requirements. The distributed MST maintains compatibility with various sequence parallelism techniques, such as Megatron-LM and Ring Attention, ensuring scalability and flexibility in different training environments.
The researchers conducted extensive experiments to validate the efficacy of MST. They trained Llama3-8B and Llama2 models with MST, significantly improving sequence length capabilities. For instance, MST enabled the training of Llama3-8B with a context length of up to 60k on a single A100 GPU, outperforming standard implementations by 12 to 20 times in terms of sequence length. Furthermore, MST maintained the same training throughput as standard long-sequence training methods, ensuring that the optimization did not come at the cost of performance.
The evaluation also highlighted the scalability of MST in distributed settings. By leveraging DeepSpeed-Ulysses, MST could scale the sequence length linearly with the number of GPUs, demonstrating its potential for large-scale deployments. The memory optimization achieved by MST was particularly pronounced for the LM-Head component, which significantly reduced memory usage while having a minimal impact on execution time for longer sequences.
The paper presents a compelling solution to the memory challenges of training large-scale Transformer models with long sequences. By introducing the MINI-SEQUENCE TRANSFORMER, the researchers offer a methodology that optimizes memory usage through mini-sequence processing and activation recomputation. This approach reduces the memory footprint and maintains high efficiency and accuracy, making it a valuable addition to existing training frameworks. The successful implementation and evaluation of MST underscore its potential to enhance the scalability and performance of long-sequence training in NLP and other domains.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech at the Indian Institute of Technology (IIT), Bhubaneswar. An AI enthusiast, she enjoys staying updated on the latest advancements. Shreya is particularly interested in the real-life applications of cutting-edge technology, especially in the field of data science.









