
Nvidia AI Releases BigVGAN v2: A State-of-the-Art Neural Vocoder Transforming Audio Synthesis
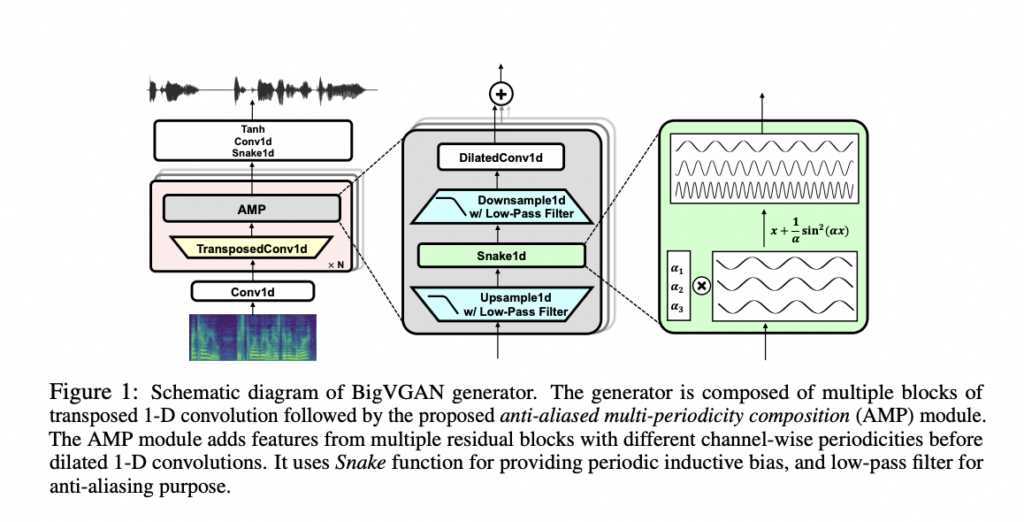
In the rapidly developing field of audio synthesis, Nvidia has recently introduced BigVGAN v2. This neural vocoder breaks previous records for audio creation speed, quality, and adaptability by converting Mel spectrograms into high-fidelity waveforms. This team has thoroughly examined the main enhancements and ideas that set BigVGAN v2 apart.
One of BigVGAN v2’s most notable features is its unique inference CUDA kernel, which combines fused upsampling and activation processes. With this breakthrough, performance has been greatly increased, with Nvidia’s A100 GPUs attaining up to three times faster inference speeds. BigVGAN v2 assures that high-quality audio may be synthesized more efficiently than ever before by streamlining the processing pipeline, which makes it an invaluable tool for real-time applications and massive audio projects.
Nvidia has also improved BigVGAN v2’s discriminator and loss algorithms significantly. The unique model uses a multi-scale Mel spectrogram loss in conjunction with a multi-scale sub-band constant-Q transform (CQT) discriminator. Improved fidelity in the synthesized waveforms results from this twofold upgrade, which makes it easier to analyze audio quality during training in a more accurate and subtle manner. BigVGAN v2 can now more accurately record and replicate the minute nuances of a wide range of audio formats, including intricate musical compositions and human speech.
The training regimen for BigVGAN v2 makes use of a large dataset that contains a variety of audio categories, such as musical instruments, speech in several languages, and ambient noises. The model has a strong capacity to generalize across various audio situations and sources with the help of a variety of training data. The end product is a universal vocoder that can be applied to a wide range of settings and is remarkably accurate in handling out-of-distribution scenarios without requiring fine-tuning.

BigVGAN v2’s pre-trained model checkpoints enable a 512x upsampling ratio and sampling speeds up to 44 kHz. In order to meet the requirements of professional audio production and research, this feature guarantees that the generated audio maintains high resolution and fidelity. BigVGAN v2 produces audio of unmatched quality, whether it is used to create realistic environmental soundscapes, lifelike synthetic voices, or sophisticated instrumental compositions.
Nvidia is opening up a wide range of applications in industries, including media and entertainment, assistive technology, and more, with the innovations in BigVGAN v2. BigVGAN v2’s improved performance and adaptability make it a priceless tool for researchers, developers, and content producers who want to push the limits of audio synthesis.
Neural vocoding technology has advanced significantly with the release of Nvidia’s BigVGAN v2. It is an effective tool for producing high-quality audio because of its sophisticated CUDA kernels, improved discriminator and loss functions, variety of training data, and high-resolution output capabilities. With its promise to transform audio synthesis and interaction in the digital age, Nvidia’s BigVGAN v2 establishes a new benchmark in the industry.
Check out the Model and Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.









