
MLPs vs KANs: Evaluating Performance in Machine Learning, Computer Vision, NLP, and Symbolic Tasks
Multi-layer perceptrons (MLPs) have become essential components in modern deep learning models, offering versatility in approximating nonlinear functions across various tasks. However, these neural networks face challenges in interpretation and scalability. The difficulty in understanding learned representations limits their transparency, while expanding the network scale often proves complex. Also, MLPs rely on fixed activation functions, potentially constraining their adaptability. Researchers have identified these limitations as significant hurdles in advancing neural network capabilities. Consequently, there is a growing need for alternative architectures that can address these challenges while maintaining or improving the performance of traditional MLPs in tasks such as classification, regression, and feature extraction.
Researchers have made considerable advancements in Kolmogorov-Arnold Networks (KANs) to address the limitations of MLPs. Various approaches have been explored, including replacing B-spline functions with alternative mathematical representations such as Chebyshev polynomials, wavelet functions, and orthogonal polynomials. These modifications aim to enhance KANs’ properties and performance. Furthermore, KANs have been integrated with existing network architectures like convolutional networks, vision transformers, U-Net, Graph Neural Networks (GNNs), and Neural Radiance Fields (NeRF). These hybrid approaches seek to utilize the strengths of KANs in diverse applications, ranging from image classification and medical image processing to graph-related tasks and 3D reconstruction. However, despite these improvements, a comprehensive and fair comparison between KANs and MLPs still needs to understand their relative capabilities and potential fully.
Researchers from the National University of Singapore conducted a fair and comprehensive comparison between KANsn and MLPs. The researchers control parameters and FLOPs for both network types, evaluating their performance across diverse domains, including symbolic formula representation, machine learning, computer vision, natural language processing, and audio processing. This approach ensures a balanced assessment of the two architectures’ capabilities. The study also investigates the impact of activation functions on network performance, particularly B-spline. The research extends to examining the networks’ behavior in continual learning scenarios, challenging previous findings on KAN’s superiority in this area. By providing a thorough and equitable comparison, the study seeks to offer valuable insights for future research on KAN and potential MLP alternatives.
The study aims to provide a comprehensive comparison between KANs and MLPs across diverse domains. The researchers designed experiments to evaluate performance under controlled conditions, ensuring either equal parameter counts or FLOPs for both network types. The assessment covers a wide range of tasks, including machine learning, computer vision, natural language processing, audio processing, and symbolic formula representation. This broad scope allows for a thorough examination of each architecture’s strengths and weaknesses in various applications. To maintain consistency, all experiments utilized the Adam optimizer with a batch size of 128 and learning rates of either 1e-3 or 1e-4. The use of a single RTX3090 GPU for all experiments further ensures the comparability of results across different tasks.

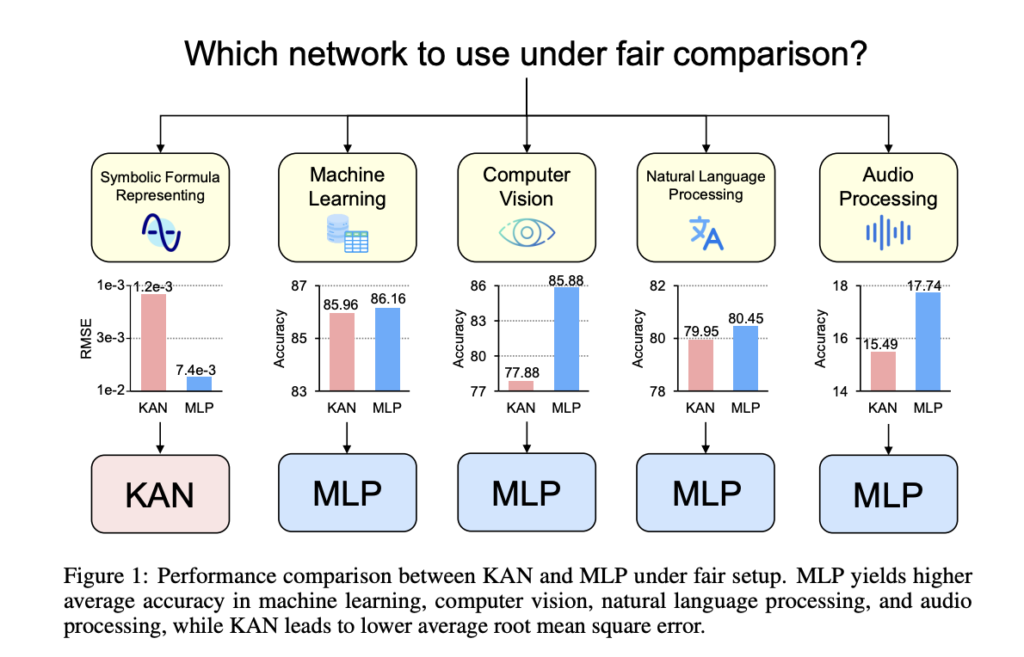
In machine learning tasks across eight datasets, MLPs generally outperformed KANs. The study used varied configurations for both architectures, including different hidden layer widths, activation functions, and normalization techniques. KANs were tested with various B-spline parameters and expanded input ranges. After 20-epoch training runs, MLPs showed superior performance on six datasets, while KANs matched or exceeded MLPs on two. This suggests MLPs maintain an overall advantage in machine learning applications, though KANs’ occasional superiority warrants further investigation through architecture ablation studies.
In computer vision experiments across eight datasets, MLPs consistently outperformed KANs. Both architectures were tested with various configurations, including different hidden layer widths and activation functions. KANs used varying B-spline parameters. After 20-epoch training runs, MLPs showed superior performance on all datasets, whether compared by equal parameter counts or FLOPs. The conductive bias from KAN’s spline functions proved ineffective for visual tasks. This suggests MLPs maintain a significant advantage in computer vision applications, indicating that KAN’s architectural differences may not be well-suited for processing visual data.
In audio and text classification tasks across four datasets, MLPs generally outperformed KANs. Various configurations were tested for both architectures. MLPs consistently excelled in audio tasks and on the AG News dataset. Results were mixed for the CoLA dataset, with KANs showing an advantage when controlling for parameters, but not when controlling for FLOPs due to their higher computational requirements. Overall, MLPs emerged as the preferred choice for audio and text tasks, demonstrating more consistent performance across datasets and evaluation metrics. This suggests MLPs remain more effective for processing audio and textual data compared to KANs.
In symbolic formula representation tasks across eight datasets, KANs generally outperformed MLPs. With equal parameter counts, KANs excelled in 7 out of 8 datasets. When controlling for FLOPs, KANs’ performance was comparable to MLPs due to higher computational complexity, outperforming on two datasets and underperforming on one. Overall, KANs demonstrated superior capability in representing symbolic formulas compared to traditional MLPs.
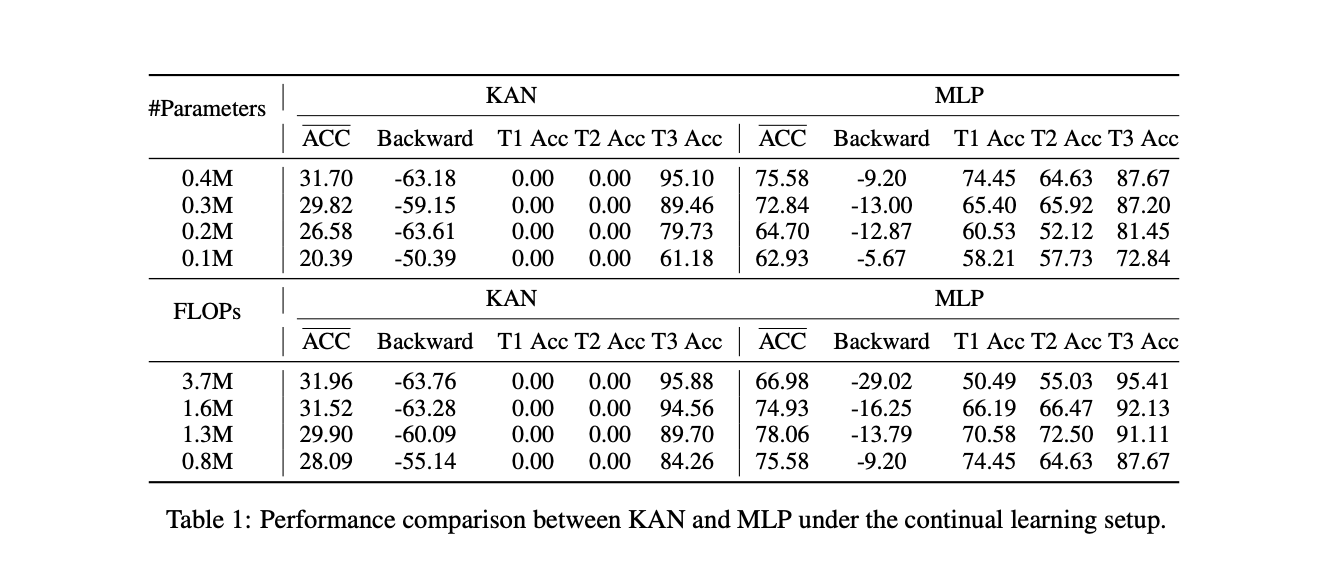
This comprehensive study compared KANs and MLPs across various tasks. KANs, viewed as a special type of MLP with learnable B-spline activation functions, only showed advantages in symbolic formula representation. MLPs outperformed KANs in machine learning, computer vision, natural language processing, and audio tasks. Interestingly, MLPs with B-spline activations matched or surpassed KAN performance across all tasks. In class-incremental learning, KANs exhibited more severe forgetting issues than MLPs. These findings provide valuable insights for future research on neural network architectures and their applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.











