
Mixtures of In-Context Learners: A Robust AI Solution for Managing Memory Constraints and Improving Classification Accuracy in Transformer-Based NLP Models
Natural language processing (NLP) continues to evolve with new methods like in-context learning (ICL), which offers innovative ways to enhance large language models (LLMs). ICL involves conditioning models on specific example demonstrations without directly modifying the model’s parameters. This method is especially valuable for training LLMs quickly for various tasks. However, ICL can be highly resource-intensive, especially in Transformer-based models where memory demands scale with the number of input examples. This limitation means that as the number of demonstrations increases, both computational complexity and memory usage grow significantly, potentially exceeding the models’ processing capacity and impacting performance. As NLP systems aim for greater efficiency and robustness, optimizing how demonstrations are handled in ICL has become a crucial research focus.
A key issue ICL addresses is how to effectively use demonstration data without exhausting computational resources or memory. In traditional setups, ICL implementations have relied on concatenating all demonstrations into a single sequence, a method known as concat-based ICL. However, this approach must distinguish each demonstration’s quality or relevance, often leading to suboptimal performance. Also, concat-based ICL must work on contextual limitations when handling large datasets, which may inadvertently include irrelevant or noisy data. This inefficiency makes training more resource-intensive and negatively affects model accuracy. Selecting demonstrations that accurately represent task requirements while managing memory demands remains a significant hurdle for effective in-context learning.
Concatenation-based methods, while straightforward, need to improve in terms of efficiently using available demonstrations. These methods combine all examples without regard for each one’s relevance, often leading to redundancy and memory overload. Current techniques largely rely on heuristics, which lack precision and scalability. This limitation, coupled with the rising computational expense, creates a bottleneck that hampers the potential of ICL. Moreover, concatenating all examples means that the self-attention mechanism in Transformer models, which scales quadratically with input length, further intensifies memory strain. This quadratic scaling challenge is a primary obstacle in enabling ICL to operate effectively across varied datasets and tasks.
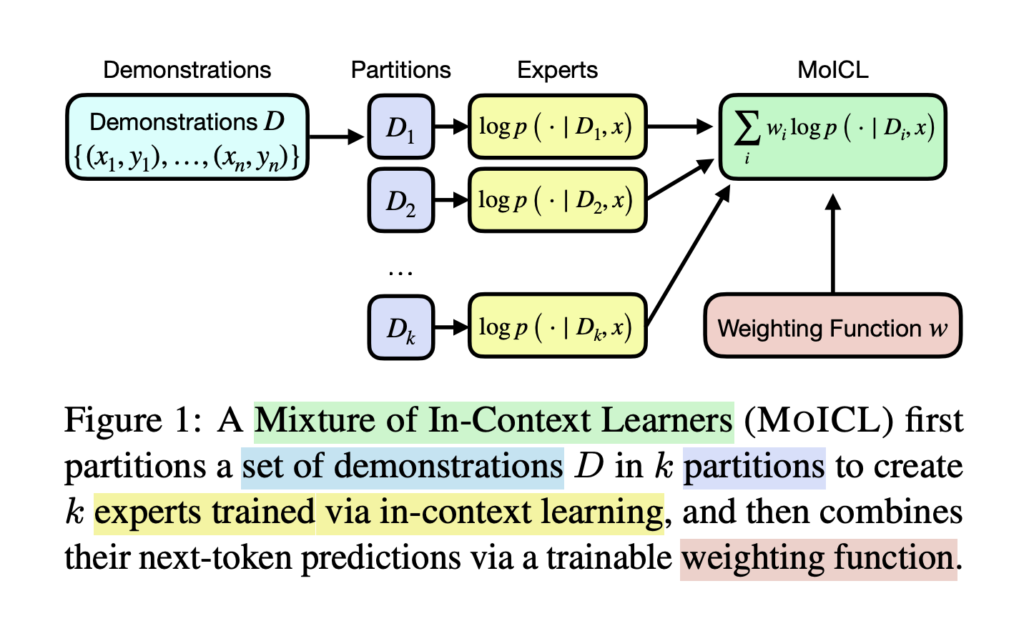
Researchers from the University of Edinburgh and Miniml.AI developed the Mixtures of In-Context Learners (MoICL) method. MoICL introduces a new framework for handling demonstrations by dividing them into smaller, specialized subsets known as “experts.” Each expert subset processes a portion of the demonstrations and produces a predictive output. A weighting function, designed to optimize the use of each expert subset, dynamically merges these outputs. This function adjusts based on the dataset and task requirements, enabling the model to utilize memory resources efficiently. MoICL thus provides a more adaptable and scalable approach to in-context learning, demonstrating notable performance improvements over traditional methods.

The mechanism underlying MoICL centers on its dynamic weighting function, which combines predictions from expert subsets to form a final, comprehensive output. Researchers can choose between scalar weights or a hyper-network, with each option affecting the model’s adaptability. Scalar weights, initialized equally, allow each expert’s contribution to be tuned during training. Alternatively, a hyper-network can generate weights based on context, optimizing results for different input subsets. This adaptability enables MoICL to function effectively with varying types of models, making it versatile for various NLP applications. MoICL’s partitioning system also reduces computational costs by limiting the need to process the entire dataset instead of selectively prioritizing relevant information.
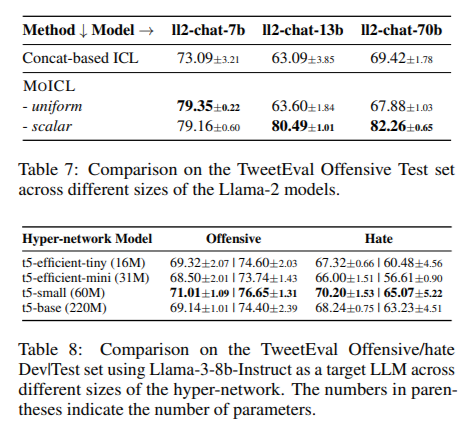
In tests across seven classification tasks, MoICL consistently outperformed standard ICL methods. For example, it achieved up to 13% higher accuracy on datasets like TweetEval, where it reached 81.33% accuracy, and improved robustness to noisy data by 38%. The system also demonstrated resilience to label imbalances (up to a 49% improvement) and out-of-domain data (11% better handling). Unlike conventional methods, MoICL maintains stable performance even with imbalanced datasets or when exposed to out-of-domain demonstrations. By using MoICL, the researchers achieved enhanced memory efficiency and faster processing times, proving it to be both computationally and operationally efficient.
Key takeaways from the research:
Performance Gains: MoICL showed an accuracy improvement of up to 13% on TweetEval compared to standard methods, with significant gains in classification tasks.
Noise and Imbalance Robustness: The method improved resilience to noisy data by 38% and managed imbalanced label distributions by 49% better than conventional ICL methods.
Efficient Computation: MoICL reduced inference times without sacrificing accuracy, showing data and memory efficiency.
Generalizability: MoICL demonstrated strong adaptability to different model types and NLP tasks, providing a scalable solution for memory-efficient learning.
Out-of-Domain Handling: MoICL is robust against unexpected data variations, with a documented 11% improvement in managing out-of-domain examples.

In conclusion, MoICL represents a significant advancement in ICL by overcoming memory constraints and delivering consistently higher performance. By leveraging expert subsets and applying weighting functions, it offers a highly efficient method for demonstration selection. This method mitigates the limitations of concat-based approaches and delivers robust accuracy across varied datasets, making it highly relevant for future NLP tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.









