
Meta AI Releases MobileLLM 125M, 350M, 600M and 1B Model Checkpoints
The widespread adoption of large language models (LLMs) has ushered in significant advancements across fields such as conversational AI, content generation, and on-device applications. However, the heavy reliance on extensive cloud resources to deploy these models raises concerns about latency, cost, and environmental sustainability. Trillion-parameter models like GPT-4 demand immense computational power, making the financial and energy costs of cloud-based LLMs increasingly untenable. These challenges are further exacerbated by the constraints of mobile hardware in terms of memory and processing power, necessitating the development of smaller, more efficient models suitable for mobile deployment.
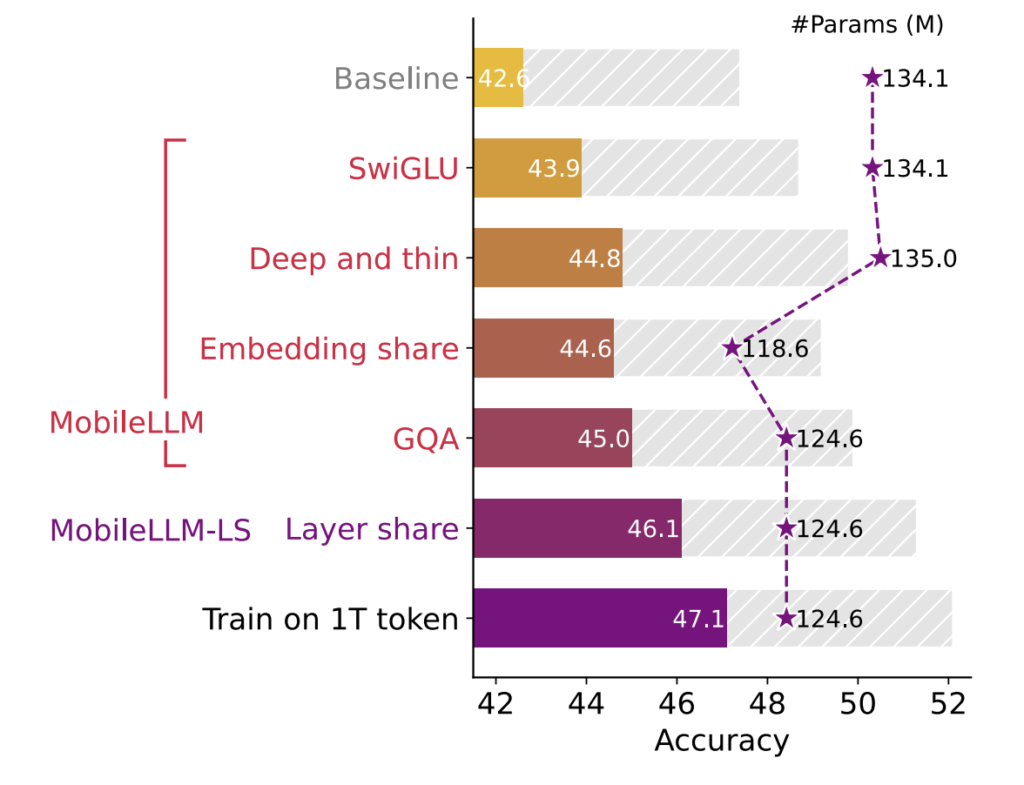
Meta has recently released MobileLLM, a set of language model checkpoints with varying sizes: 125M, 350M, 600M, and 1B parameters. The release aims to optimize the deployment of LLMs on mobile devices, providing models with a sub-billion parameter count that offer competitive performance while being resource-efficient. Available on Hugging Face, these models bring advanced NLP capabilities to mobile devices without relying heavily on cloud resources, which translates into reduced latency and operational costs. MobileLLM leverages a deep and thin architecture, defying the traditional scaling laws (Kaplan et al., 2020) that emphasize the need for more parameters for improved performance. Instead, it focuses on depth over width, enhancing its ability to capture abstract concepts and improve final performance. These models are available on the Hugging Face Hub and can be seamlessly integrated with the Transformers library.
MobileLLM employs several key innovations, making it distinct from previous sub-billion parameter models. One of the primary techniques used is embedding sharing, where the same weights are reused between input and output layers, maximizing weight utilization while reducing the model size. Additionally, the model utilizes grouped query attention (GQA), adopted from Ainslie et al. (2023), which optimizes attention mechanisms and improves efficiency. Another notable feature is immediate block-wise weight sharing, which involves replicating weights between adjacent blocks to reduce latency without increasing the model size significantly. This approach reduces the need for weight movement, leading to faster execution times. These technical details contribute to making MobileLLM highly efficient and capable of running on-device, with minimal reliance on cloud computing.
The importance of MobileLLM lies in its ability to bring complex language modeling to mobile devices without compromising on performance. In zero-shot tasks, MobileLLM outperformed previous state-of-the-art (SOTA) models of similar size by 2.7% for the 125M model and by 4.3% for the 350M model. This demonstrates the model’s potential for on-device applications such as chat and API calling. In an API calling task, the MobileLLM-350M model achieved a comparable exact match score to the larger LLaMA-v2 7B model, showcasing its competitive performance despite its smaller size. These advancements highlight how small, efficient models like MobileLLM can play a significant role in reducing latency and energy consumption for mobile use cases.


In conclusion, Meta’s MobileLLM provides an innovative solution to the growing concerns around the computational and environmental costs of large-scale LLMs. By focusing on depth over width, embedding sharing, grouped query attention, and immediate block-wise weight sharing, MobileLLM manages to deliver high performance without the need for extensive resources. This release represents a significant step forward in bringing the power of LLMs to mobile devices, enhancing their capabilities for a range of applications, from chat to API integration, all while maintaining efficiency and reducing operational costs. As mobile technology continues to advance, models like MobileLLM will be instrumental in pushing the boundaries of what can be achieved on-device.
Check out the Paper and Full Release on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.








