
HyPO: A Hybrid Reinforcement Learning Algorithm that Uses Offline Data for Contrastive-based Preference Optimization and Online Unlabeled Data for KL Regularization

A critical aspect of AI research involves fine-tuning large language models (LLMs) to align their outputs with human preferences. This fine-tuning ensures that AI systems generate useful, relevant, and aligned responses with user expectations. The current paradigm in AI emphasizes learning from human preference data to refine these models, addressing the complexity of manually specifying reward functions for various tasks. The two predominant techniques in this area are online reinforcement learning (RL) and offline contrastive methods, each offering unique advantages and challenges.
A central challenge in fine-tuning LLMs to reflect human preferences is the limited coverage of static datasets. These datasets may need to adequately represent the diverse and dynamic range of human preferences in real-world applications. The issue of dataset coverage becomes particularly pronounced when models are trained exclusively on pre-collected data, potentially leading to suboptimal performance. This problem underscores the need for methods to effectively leverage static datasets and real-time data to enhance model alignment with human preferences.
Existing techniques for preference fine-tuning in LLMs include online RL methods, such as Proximal Policy Optimization (PPO), and offline contrastive methods, like Direct Preference Optimization (DPO). Online RL methods involve a two-stage procedure where a reward model is trained on a fixed offline preference dataset, followed by RL training using on-policy data. This approach benefits from real-time feedback but is computationally intensive. In contrast, offline contrastive methods optimize policies based solely on pre-collected data, avoiding the need for real-time sampling but potentially suffering from overfitting and limited generalization capabilities.
Researchers from Carnegie Mellon University, Aurora Innovation, and Cornell University introduced a novel method called Hybrid Preference Optimization (HyPO). This hybrid approach combines the power of both online and offline techniques, aiming to improve model performance while maintaining computational efficiency. HyPO integrates offline data for initial preference optimization. It uses online unlabeled data for Kullback-Leibler (KL) regularization, ensuring the model remains close to a reference policy and better generalizes beyond the training data.

HyPO utilizes a sophisticated algorithmic framework that leverages offline data for the DPO objective and online samples to control the reverse KL divergence. The algorithm iteratively updates the model’s parameters by optimizing the DPO loss while incorporating a KL regularization term derived from online samples. This hybrid approach effectively addresses the deficiencies of purely offline methods, such as overfitting and insufficient dataset coverage, by incorporating the strengths of online RL methods without their computational complexity.
The performance of HyPO was evaluated on several benchmarks, including the TL;DR summarization task and general chat benchmarks like AlpacaEval 2.0 and MT-Bench. The results were impressive, with HyPO achieving a win rate of 46.44% on the TL;DR task using the Pythia 1.4B model, compared to 42.17% for the DPO method. For the Pythia 2.8B model, HyPO achieved a win rate of 50.50%, significantly outperforming DPO’s 44.39%. Additionally, HyPO demonstrated superior control over reverse KL divergence, with values of 0.37 and 2.51 for the Pythia 1.4B and 2.8B models, respectively, compared to 0.16 and 2.43 for DPO.
In general chat benchmarks, HyPO also showed notable improvements. For instance, in the MT-Bench evaluation, HyPO fine-tuned models achieved scores of 8.43 and 8.09 in the first and second turn averages, respectively, surpassing the DPO-fine-tuned models’ scores of 8.31 and 7.89. Similarly, in the AlpacaEval 2.0, HyPO achieved 30.7% and 32.2% win rates for the 1st and 2nd turns, compared to DPO’s 28.4% and 30.9%.
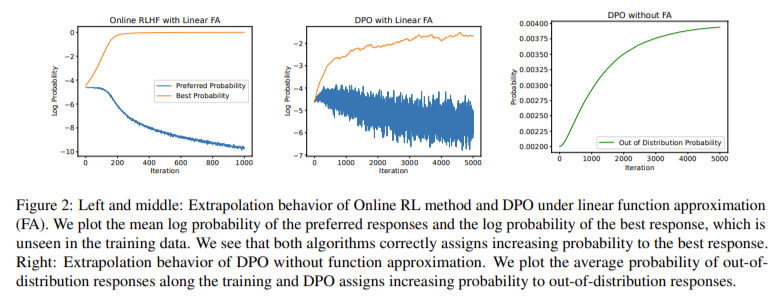
The empirical results highlight HyPO’s ability to mitigate overfitting issues commonly observed in offline contrastive methods. For example, when trained on the TL;DR dataset, HyPO maintained a mean validation KL score significantly lower than that of DPO, indicating better alignment with the reference policy and reduced overfitting. This ability to leverage online data for regularization helps HyPO achieve more robust performance across various tasks.

In conclusion, the introduction of hybrid preference optimization (HyPO), which effectively combines offline and online data, addresses the limitations of existing methods and enhances the alignment of large language models with human preferences. The performance improvements demonstrated in empirical evaluations underscore the potential of HyPO to deliver more accurate and reliable AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.










