
Google DeepMind Introduces Diffusion Model Predictive Control (D-MPC): Combining Multi-Step Action Proposals and Dynamics Models Using Diffusion Models for Online MPC
Model Predictive Control (MPC), or receding horizon control, aims to maximize an objective function over a planning horizon by leveraging a dynamics model and a planner to select actions. The flexibility of MPC allows it to adapt to novel reward functions at test time, unlike policy learning methods that focus on a fixed reward. Diffusion models learn world dynamics and action sequence proposals from offline data to improve MPC. A “sample, score, and rank” (SSR) method refines action selection, offering a simple alternative to more complex optimization techniques.
Model-based methods use dynamics models, with Dyna-style techniques learning policies online or offline, and MPC approaches utilizing models for runtime planning. Diffusion-based methods like Diffuser and Decision Diffuser apply joint trajectory models to predict state-action sequences. Some methods factorize the dynamics and action proposals for added flexibility. Multi-step diffusion modeling allows these approaches to generate trajectory-level predictions, improving their ability to adapt to new environments and rewards. Compared to more complex trajectory optimization approaches, these methods often simplify planning or policy generation.
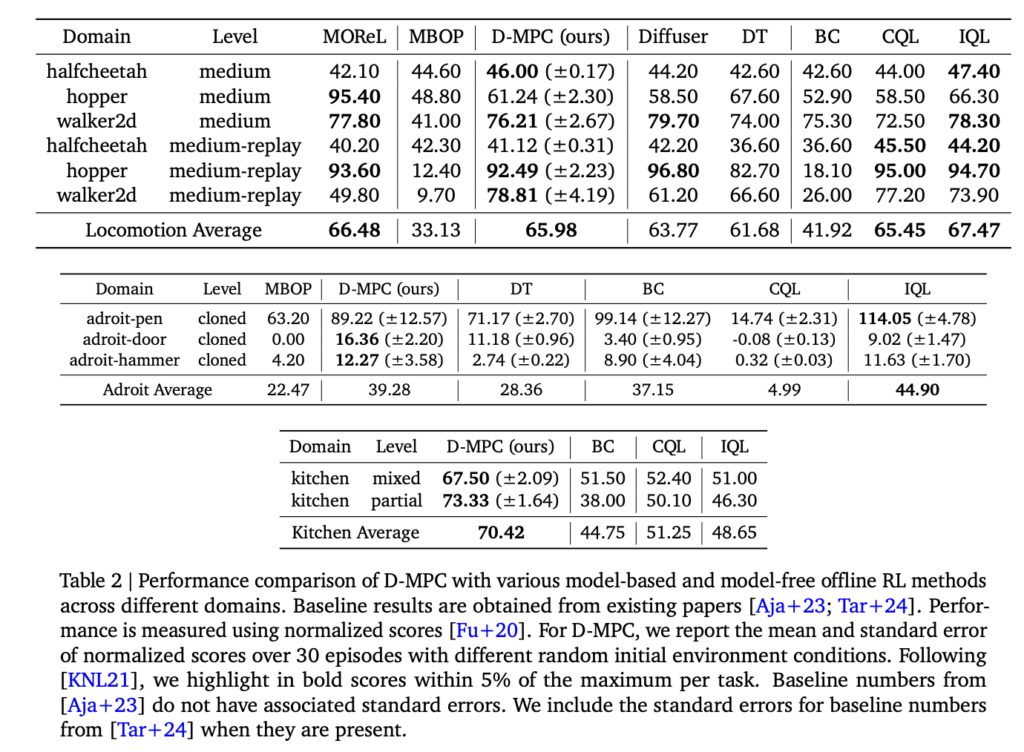
Researchers from Google DeepMind introduced Diffusion Model Predictive Control (D-MPC), an approach that integrates multi-step action proposals and dynamics models using diffusion models for online MPC. On the D4RL benchmark, D-MPC outperforms existing model-based offline planning methods and competes with state-of-the-art reinforcement learning methods. D-MPC also adapts to novel dynamics and optimizes new rewards at runtime. The key elements, including multi-step dynamics, action proposals, and an SSR planner, are individually effective and even more powerful when combined.
The proposed method involves a multi-step diffusion-based extension of model-based offline planning. Initially, it learns the dynamics model, action proposals, and a heuristic value function from an offline dataset of trajectories. During planning, the system alternates between taking actions and generating the next sequence of actions using a planner. The SSR planner samples multiple action sequences evaluates them using the learned models, and selects the best option. This approach adapts easily to new reward functions and can be fine-tuned for changing dynamics using small amounts of new data.

The experiments evaluate D-MPC’s effectiveness in several areas: performance improvement over offline MPC methods, adaptability to new rewards and dynamics, and distillation into fast reactive policies. Tested on D4RL locomotion, Adroit, and Franka Kitchen tasks, D-MPC outperforms methods like MBOP and closely rivals others such as Diffuser and IQL. Notably, it generalizes well to rewards and adapts to hardware defects, improving performance after fine-tuning. Ablation studies show that using multi-step diffusion models for both action proposals and dynamics significantly enhances long-horizon prediction accuracy and overall task performance compared to single-step or transformer models.
In conclusion, the study introduced D-MPC, which enhances MPC by using diffusion models for multi-step action proposals and dynamics predictions. D-MPC reduces compounding errors and demonstrates strong performance on the D4RL benchmark, surpassing current model-based planning methods and competing with state-of-the-art reinforcement learning approaches. It excels at adapting to new rewards and dynamics during run time but requires replanning at each step, which is slower than reactive policies. Future work will focus on speeding up sampling and extending D-MPC to handle pixel observations using latent representation techniques.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.








