
Formatron: A High-Performance Constrained Decoding Python Library that Allows Users to Control the Output Format of Language Models with Minimal Overhead
Language models (LMs), while powerful in generating human-like text, often produce unstructured and inconsistent outputs. The lack of structure in responses poses challenges in real-world applications, especially in long and extensive responses. It becomes difficult to extract specific information, integrate with systems expecting structured data, and present information in formats like tables or lists that users prefer for better comprehension. The ability to control and define the format of language model outputs is thus crucial for enhancing efficiency, accuracy, and user satisfaction.
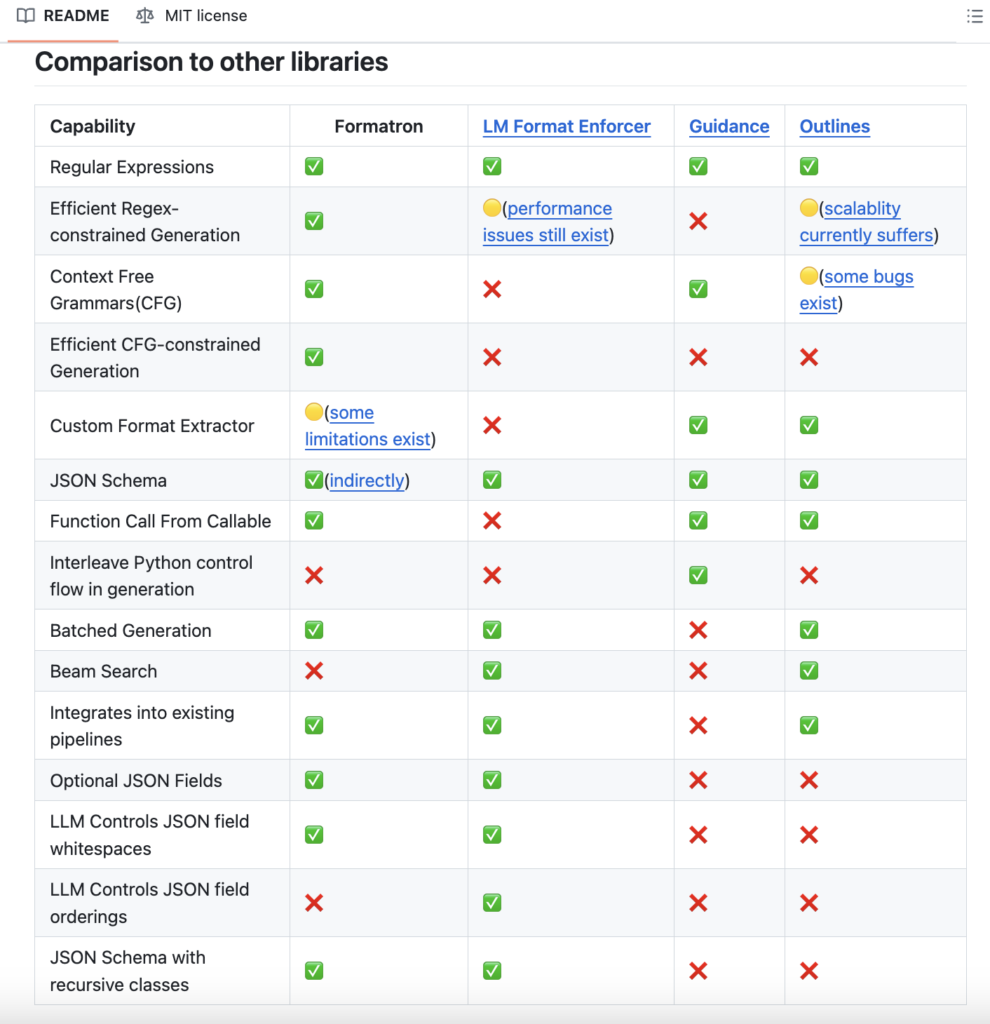
Language models have made significant advancements in generating text in various formats. Existing tools and libraries for working with LMs, such as Guidance, Outlines, and LMQL, typically offer end-to-end inference pipelines. the tools for post-processing text into a specific format may be labor-intensive, error-prone, or inefficient, particularly when dealing with complex data or large volumes of text.
The researchers introduce Formatron, a tool designed to address the challenge of unstructured and inconsistent outputs generated by language models. Formatron provides users flexibility and an efficient way to specify desired output formats using natural language-like expressions. This approach lowers the barrier for users without extensive programming expertise and offers a more intuitive method for defining formats. Additionally, Formatron supports complex formatting requirements through the use of regular expressions and context-free grammar.
Formatron’s methodology aims to provide a versatile and efficient means to specify the desired format of LMs outputs. It supports various formatting techniques, including natural language-like expressions for easy user access, regular expressions, and context-free grammar for more complex formatting needs. A key feature is its ability to generate structured data, particularly JSON, based on Pydantic models or JSON schemas, which is crucial for integrating with other systems. Additionally, Formatron supports batch inference, allowing the simultaneous processing of multiple sequences with different formats, thus enhancing efficiency. Although specific performance metrics may vary depending on the complexity of the format and input size, Formatron generally aims to minimize overhead and seamlessly integrate with existing codebases.

In conclusion, Formatron presents a compelling solution to the problem of unstructured and inconsistent language model outputs. By introducing a flexible tool that allows users to format the output of LMs, the study highlights the potential for Formatron to improve efficiency, accuracy, and user satisfaction across various applications. The methodology and performance of Formatron make it a valuable addition to the toolkit of developers and researchers working with language models.
Check out the GitHub Library. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.









