
ECCO: A Reproducible AI Benchmark for Evaluating Program Efficiency via Two Paradigms- Natural Language (NL) based Code Generation and History-based Code Editing
In computer science, code efficiency and correctness are paramount. Software engineering and artificial intelligence heavily rely on developing algorithms and tools that optimize program performance while ensuring they function correctly. This involves creating functionally accurate code and ensuring it runs efficiently, using minimal computational resources.
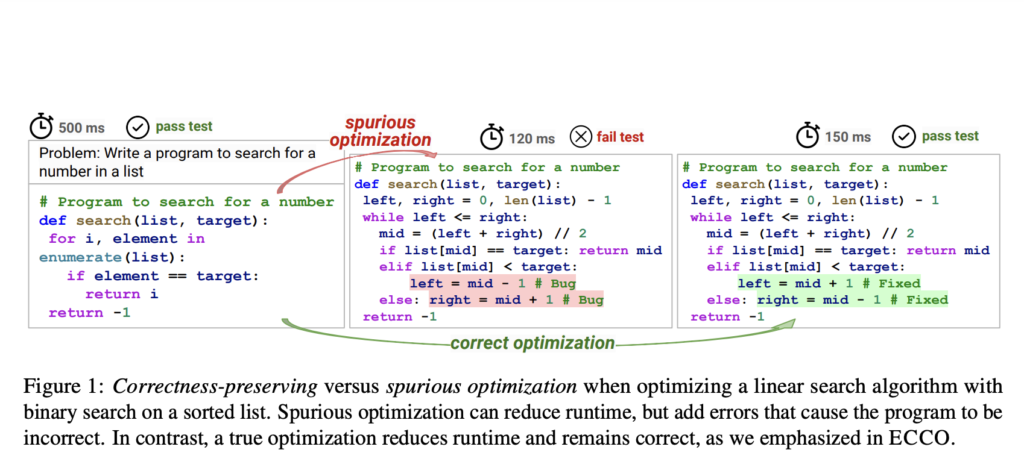
A key issue in generating efficient code is that while current language models can produce functionally correct programs, they often need more runtime and memory usage optimization. This inefficiency can be detrimental, especially in large-scale applications where performance is critical. The ability to generate correct and efficient code remains an elusive goal. Researchers aim to address this challenge by finding methods that enhance code efficiency without compromising its correctness.
Established approaches for optimizing program efficiency include in-context learning, iterative refinement, and fine-tuning based on execution data. In-context learning involves providing models with examples and context to guide the generation of optimized code. Iterative refinement focuses on progressively improving code through repeated evaluations and adjustments. On the other hand, fine-tuning involves training models on specific datasets to enhance their performance. While these methods show promise, they often struggle to maintain the functional correctness of the code, leading to optimizations that can introduce errors.
Researchers from the Language Technologies Institute at Carnegie Mellon University introduced ECCO, a benchmark designed to evaluate program efficiency while preserving correctness. ECCO supports two paradigms: natural language-based code generation and history-based code editing. This benchmark aims to assess the efficiency of code generated by language models and provide a reliable platform for future research. Using a cloud-based execution engine called JUDGE0, ECCO ensures stable and reproducible execution outputs, regardless of local hardware differences. This setup supports over 60 programming languages, making it a versatile tool for evaluating code efficiency.

The ECCO benchmark involves a comprehensive setup using the cloud-hosted code execution engine JUDGE0, which provides consistent execution outputs. ECCO evaluates code on execution correctness, runtime efficiency, and memory efficiency. The benchmark includes over 50,000 Python solution pairs from 1,300 competitive programming problems, offering a robust dataset for assessing language models’ performance. These problems were collected from the IBM CodeNet dataset and the AlphaCode project, ensuring a diverse and extensive collection of test cases. ECCO’s evaluation setup uses Amazon EC2 instances to execute code in a controlled environment, providing accurate and reliable results.
In their experiments, the researchers explored various top-performing code generation approaches to improve program efficiency while maintaining functional correctness. They evaluated three main classes of methods: in-context learning, iterative refinement, and fine-tuning. The study found that incorporating execution information helps maintain functional correctness, while natural language feedback significantly enhances efficiency. For instance, history-based editing showed substantial improvements in program speedup and memory reduction, with methods involving natural language feedback achieving the highest speedup across models. Iterative refinement, particularly with execution feedback, consistently yielded the highest correctness rates, demonstrating the importance of execution outputs in guiding optimization.
The ECCO benchmark demonstrated that only existing methods could improve efficiency with some loss in correctness. For example, models like StarCoder2 and DeepseekCoder showed significant variations in performance across different evaluation metrics. While DeepseekCoder achieved a pass rate of 66.6% in history-based editing, it compromised correctness, highlighting the complex trade-offs between correctness and efficiency. These findings underscore the need for more robust methods to handle these trade-offs effectively. ECCO is a comprehensive testbed for future research, promoting advancements in correctness-preserving code optimization.

In conclusion, the research addresses the critical issue of generating efficient and correct code. By introducing the ECCO benchmark, the research team provided a valuable tool for evaluating and improving the performance of language models in code generation. ECCO’s comprehensive evaluation setup and extensive dataset offer a solid foundation for future efforts to develop methods that enhance code efficiency without sacrificing correctness.
Check out the Paper, GitHub, and HF Dataset. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.











