
Compositional GSM: A New AI Benchmark for Evaluating Large Language Models’ Reasoning Capabilities in Multi-Step Problems
Natural language processing (NLP) has experienced rapid advancements, with large language models (LLMs) being used to tackle various challenging problems. Among the diverse applications of LLMs, mathematical problem-solving has emerged as a benchmark to assess their reasoning abilities. These models have demonstrated remarkable performance on math-specific benchmarks such as GSM8K, which measures their capabilities to solve grade-school math problems. However, there is an ongoing debate regarding whether these models truly comprehend mathematical concepts or exploit patterns within training data to produce correct answers. This has led to a need for a deeper evaluation to understand the extent of their reasoning capabilities in handling complex, interconnected problem types.
Despite their success on existing math benchmarks, researchers identified a critical problem: most LLMs need to exhibit consistent reasoning when faced with more complex, compositional questions. While standard benchmarks involve solving individual problems independently, real-world scenarios often require understanding relationships between multiple problems, where the answer to one question must be used to solve another. Traditional evaluations do not adequately represent such scenarios, which focus only on isolated problem-solving. This creates a discrepancy between the high benchmark scores and LLMs’ practical usability for complex tasks requiring step-by-step reasoning and deeper understanding.
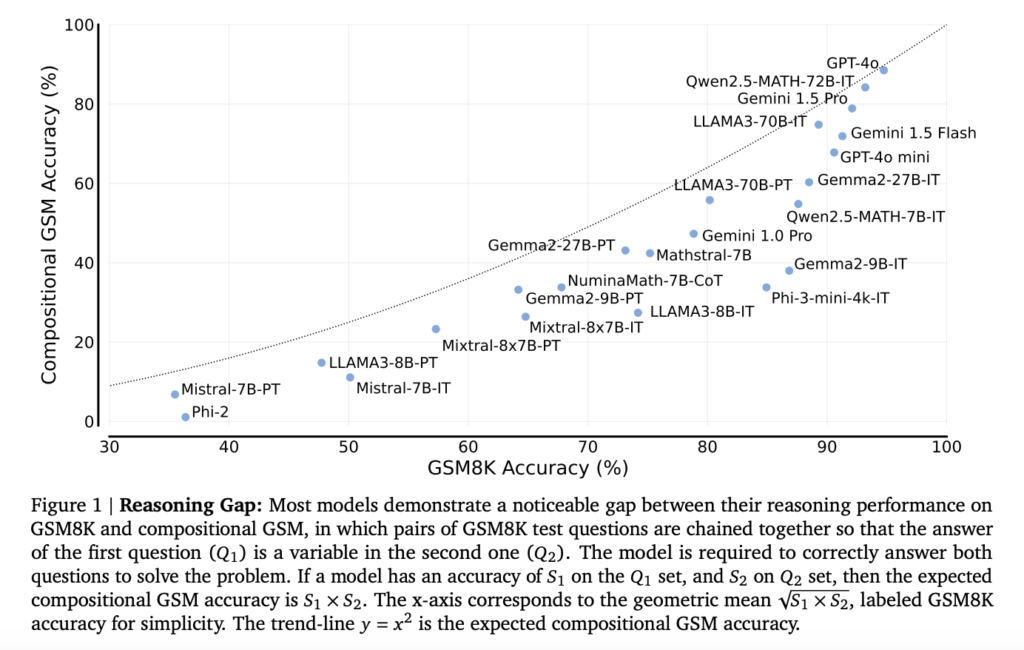
Researchers from Mila, Google DeepMind, and Microsoft Research have introduced a new evaluation method called “Compositional Grade-School Math (GSM).” This method involves chaining two separate math problems such that the solution to the first problem becomes a variable in the second problem. Using this approach, researchers can analyze the LLMs’ abilities to handle dependencies between questions, a concept that needs to be adequately captured by existing benchmarks. The Compositional GSM method offers a more comprehensive assessment of LLMs’ reasoning capabilities by introducing linked problems that require the model to carry information from one problem to another, making it necessary to solve both correctly for a successful outcome.
The evaluation was carried out using a variety of LLMs, including open-weight models like LLAMA3 and closed-weight models like GPT and Gemini families. The study included three test sets: the original GSM8K test split, a modified version of GSM8K where some variables were substituted, and the new Compositional GSM test set, each containing 1,200 examples. Models were tested using an 8-shot prompting method, where they were given several examples before being asked to solve the compositional problems. This method enabled the researchers to benchmark the models’ performance comprehensively, considering their ability to solve problems individually and in a compositional context.

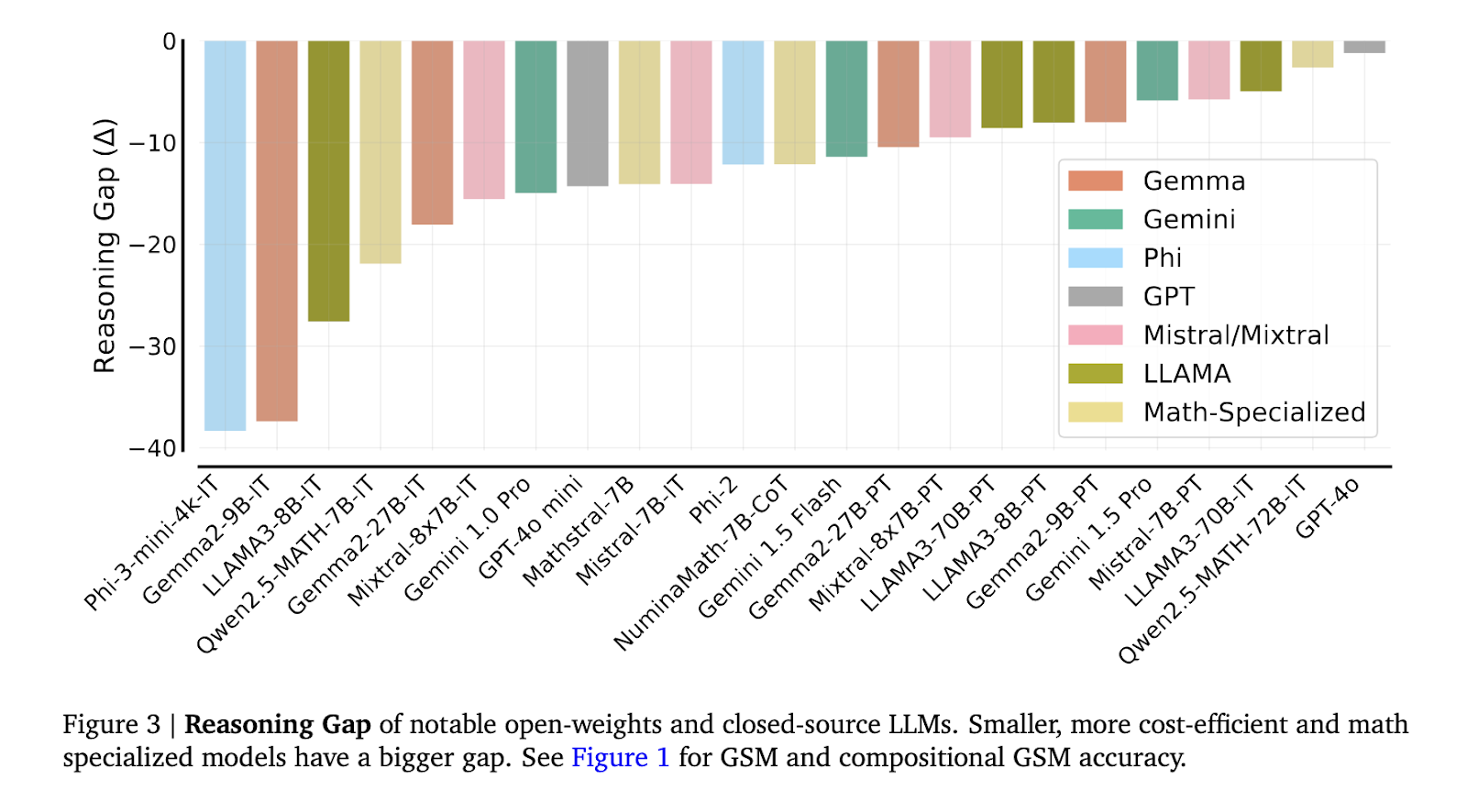
The results showed a considerable gap in reasoning abilities. For instance, cost-efficient models such as GPT-4o mini exhibited a 2 to 12 times worse reasoning gap on compositional GSM compared to their performance on the standard GSM8K. Further, math-specialized models like Qwen2.5-MATH-72B, which achieved above 80% accuracy on high-school competition-level questions, could only solve less than 60% of the compositional grade-school math problems. This substantial drop suggests that more than specialized training in mathematics is needed to prepare models for multi-step reasoning tasks adequately. Furthermore, it was observed that models like LLAMA3-8B and Mistral-7B, despite achieving high scores on isolated problems, showed a sharp decline when required to link answers between related problems.
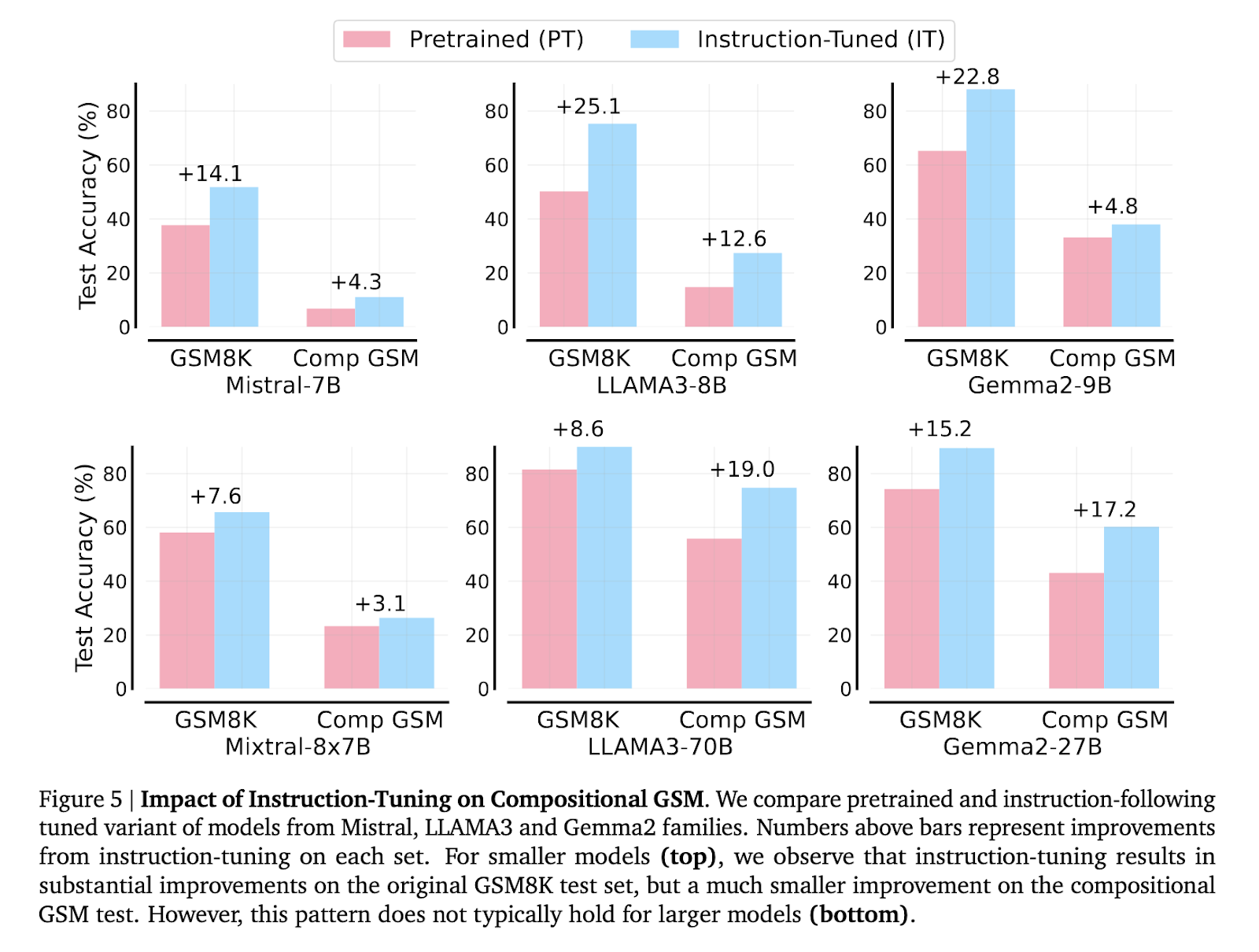
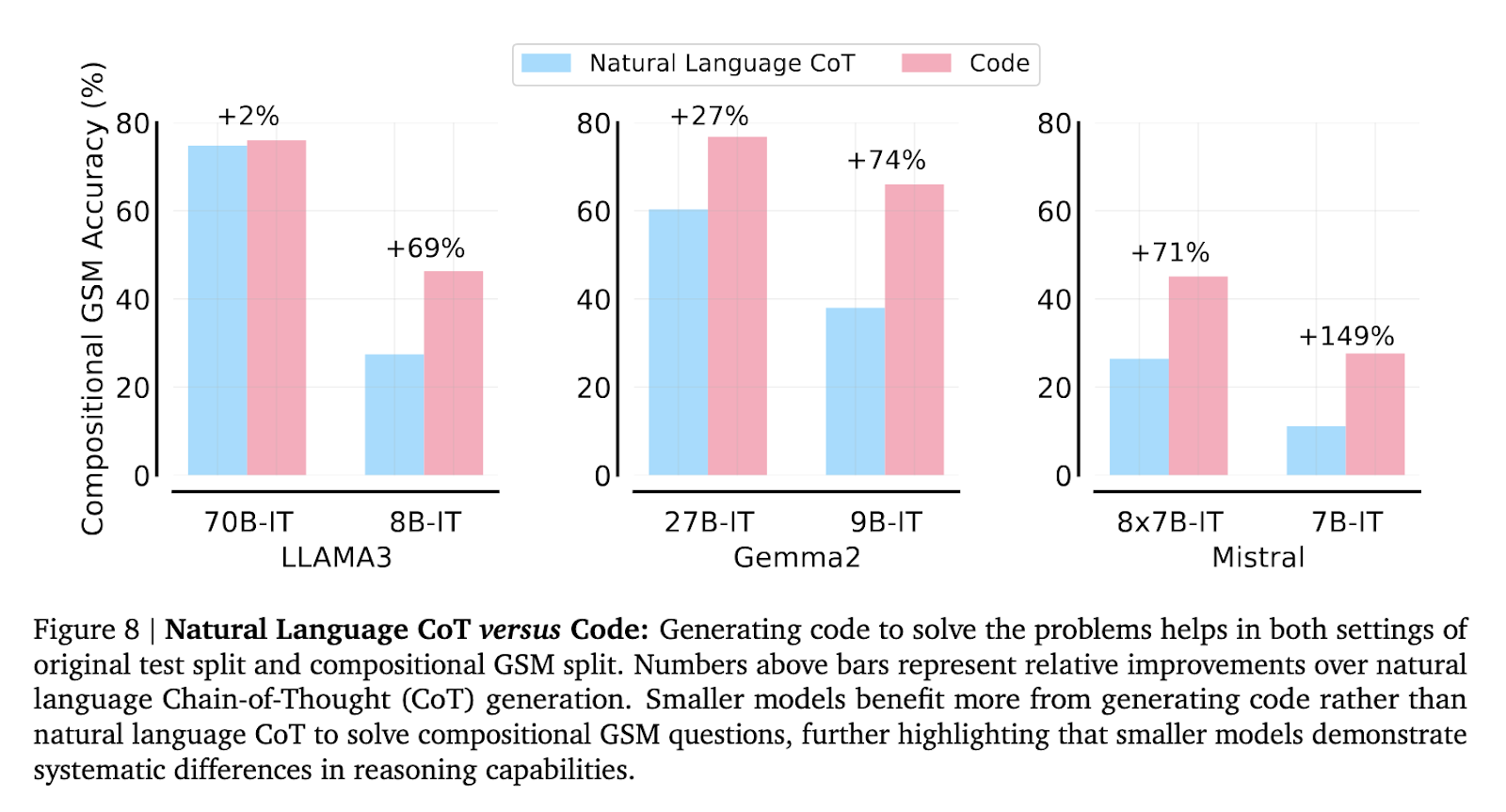
The researchers also explored the impact of instruction tuning and code generation on model performance. Instruction-tuning improved results for smaller models on standard GSM8K problems but led to only minor improvements on compositional GSM. Meanwhile, generating code solutions instead of using natural language resulted in a 71% to 149% improvement for some smaller models on compositional GSM. This finding indicates that while code generation helps reduce the reasoning gap, it does not eliminate it, and systematic differences in reasoning capabilities persist among various models.
Analysis of the reasoning gaps revealed that the performance drop was not due to test-set leakage but rather to distractions caused by additional context and poor second-hop reasoning. For example, when models like LLAMA3-70B-IT and Gemini 1.5 Pro were required to solve a second question using the answer of the first, they frequently needed to apply the solution accurately, resulting in incorrect final answers. This phenomenon, referred to as the second-hop reasoning gap, was more pronounced in smaller models, which tended to overlook crucial details when solving complex problems.
The study highlights that current LLMs, regardless of their performance on standard benchmarks, still struggle with compositional reasoning tasks. The Compositional GSM benchmark introduced in the research provides a valuable tool for evaluating the reasoning abilities of LLMs beyond isolated problem-solving. These results suggest that more robust training strategies and benchmark designs are needed to enhance the compositional capabilities of these models, enabling them to perform better in complex problem-solving scenarios. This research underscores the importance of reassessing existing evaluation methods and prioritizing the development of models capable of multi-step reasoning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.









