
CodePMP: A Scalable Preference Model Pre-training for Supercharging Large Language Model Reasoning
Large Language Models (LLMs) have made considerable advancements in natural language understanding and generation through scalable pretraining and fine-tuning techniques. However, a major challenge persists in enhancing LLMs’ reasoning abilities, particularly for complex logical and mathematical tasks. The scarcity of high-quality preference data for fine-tuning reward models (RMs) limits the effectiveness of Reinforcement Learning from Human Feedback (RLHF) approaches, which are essential for improving LLM performance in reasoning. This lack of data, which is costly and labor-intensive to collect, hinders the scalability of RMs, creating a critical bottleneck for advancing LLM capabilities in reasoning tasks such as problem-solving and decision-making.
Current solutions for improving reward models, such as Anthropic’s Preference Model Pretraining (PMP), attempt to address data efficiency by using publicly available large-scale datasets like those from Reddit or Wikipedia for pretraining. However, these datasets are not tailored for reasoning-specific tasks. Annotating data for reasoning tasks, especially for complex logical and mathematical problems, is difficult to scale, limiting the applicability of existing methods. Additionally, the computational complexity of these models makes them impractical for real-time applications, and their reliance on vast amounts of human-annotated data further constrains scalability. As a result, these methods struggle to deliver the efficiency required for fine-tuning reasoning tasks.
The researchers from the University of Chinese Academy of Sciences introduced CodePMP, a novel pretraining method that generates large-scale preference data from publicly available source code, specifically tailored for reasoning tasks. By leveraging the structured and logical nature of code, the proposed method synthesizes millions of code-preference pairs for use in training reward models. Two language models, one strong and one weak, are employed to generate chosen and rejected code responses for a given prompt, creating a rich dataset for pretraining. This innovative approach overcomes the limitations of existing methods by automating preference data generation, significantly improving the efficiency and scalability of RM fine-tuning. CodePMP enables models to generalize better across reasoning tasks, providing a cost-effective solution that reduces reliance on human-annotated data.
CodePMP involves two key components: Reward Modeling (RM) and Language Modeling (LM). In RM, the model is trained on code-preference pairs, learning to rank higher-quality responses over lower-quality ones using pairwise ranking loss. The LM component focuses on training only the chosen responses, ensuring the model retains general language understanding capabilities while improving its reasoning performance. The training dataset consists of 28 million files and 19 billion tokens sourced from GitHub, with a balanced distribution of chosen and rejected responses to ensure unbiased learning. This scalable pretraining dataset enables the model to generalize effectively across multiple reasoning tasks, improving RM fine-tuning efficiency.

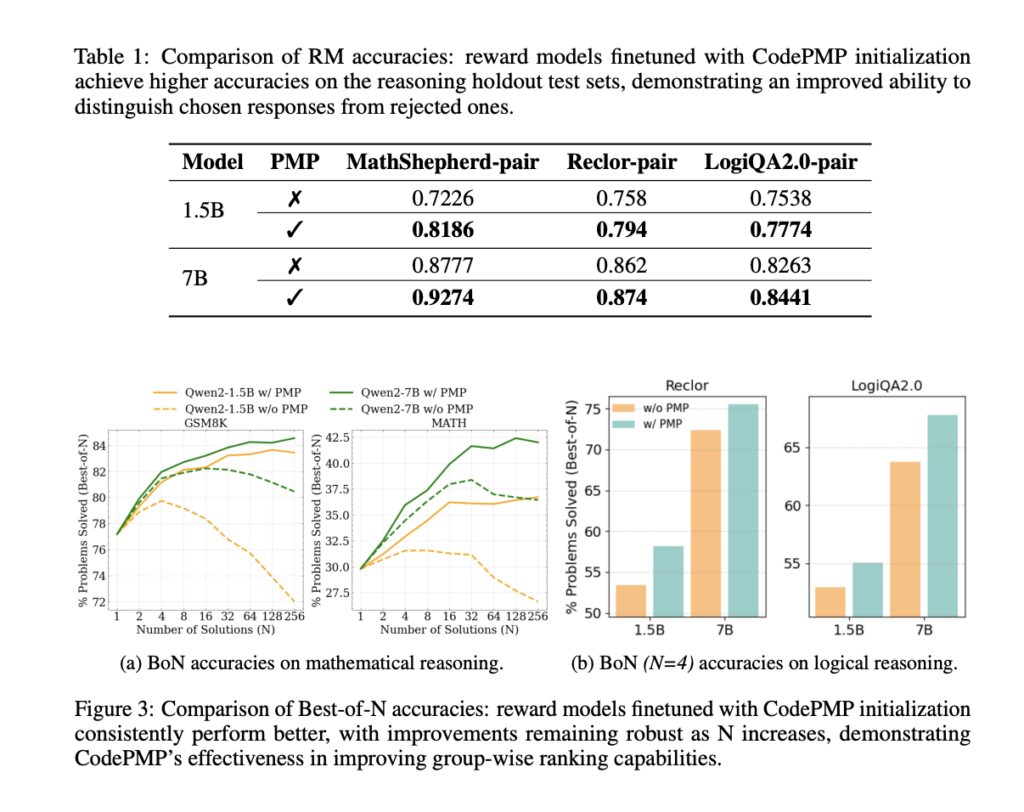
CodePMP demonstrated significant improvements in reasoning performance across mathematical and logical reasoning tasks. Models pre-trained with CodePMP consistently outperformed those without it in both RM accuracy and Best-of-N performance. These improvements were seen across both 1.5B and 7B model sizes. For example, in mathematical reasoning tasks, the model achieved substantially higher accuracy, and in logical reasoning tasks, it displayed enhanced ability to differentiate between correct and incorrect reasoning steps. The results highlight the effectiveness of CodePMP in boosting RM fine-tuning efficiency, resulting in better generalization and performance across diverse reasoning domains.

In conclusion, CodePMP presents a scalable and efficient approach to improve reasoning abilities in large language models by leveraging code-preference pairs generated from publicly available source code. This innovative method addresses the challenge of limited reasoning-specific data and significantly enhances reward model fine-tuning. The improvements achieved through CodePMP are robust across multiple reasoning tasks, indicating that it provides a scalable, cost-effective solution to enhancing LLM performance in areas requiring complex reasoning. The approach holds potential to advance LLMs’ capabilities in domains such as mathematical problem-solving, logical deduction, and decision-making.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.








