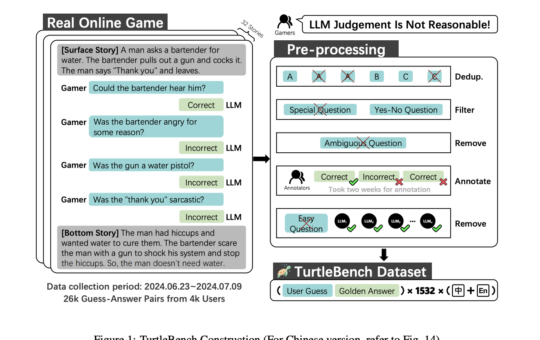
Meet TurtleBench: A Unique AI Evaluation System for Evaluating Top Language Models via Real World Yes/No Puzzles
The need for efficient and trustworthy techniques to assess the performance of Large Language Models (LLMs) is increasing as these...

The need for efficient and trustworthy techniques to assess the performance of Large Language Models (LLMs) is increasing as these...
Live Aware Labs has closed a successful seed funding round to build out its community feedback platform for game developers.Read...
Telefónica’s corporate venture capital arm, Wayra, has announced its investment in AI answer engine Perplexity. Perplexity’s AI-driven platform aims to...
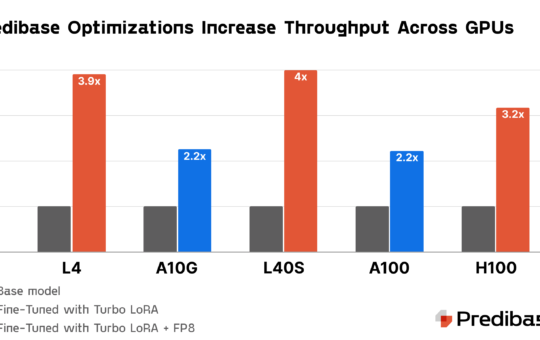
Predibase announces the Predibase Inference Engine, their new infrastructure offering designed to be the best platform for serving fine-tuned small...

Eventually, Mehrabyan says contextual intelligence will lead PicsArt to an agent-based ecosystem.Read More Source link

Four major US firms have announced plans to invest a combined £6.3 billion in UK data infrastructure. The announcement, made...

One of the most pressing challenges in the evaluation of Vision-Language Models (VLMs) is related to not having comprehensive benchmarks...

A simple letter counting experiment exposes a fundamental limitation of LLMs ChatGPT and Claude, proving they can't yet “think” like...
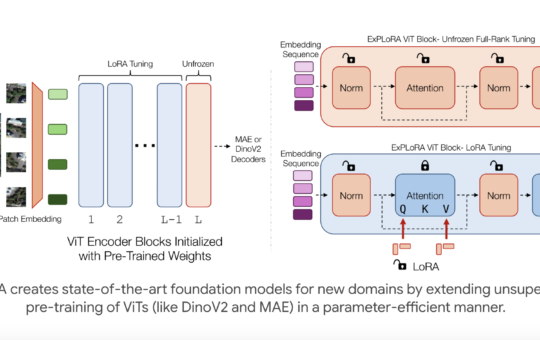
Parameter-efficient fine-tuning (PEFT) methods, like low-rank adaptation (LoRA), allow large pre-trained foundation models to be adapted to downstream tasks using...

Check on YouTube

Gamers and developers looking for their next target spec will want to pay attention to NRG esports and Intel joining...

China Telecom, one of the country’s state-owned telecom giants, has created two LLMs that were trained solely on domestically-produced chips....
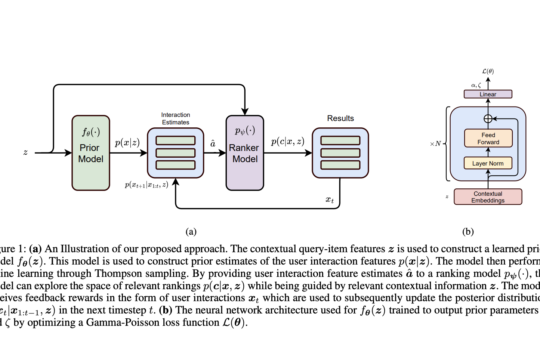
Information Retrieval (IR) systems for search and recommendations often utilize Learning-to-Rank (LTR) solutions to prioritize relevant items for user queries....

Check on YouTube

LLMs can retrieve disparate facts from their context windows, but when it comes to reasoning over their context, they struggle...

While AI improves the detection of cybersecurity threats, it simultaneously ushers in more advanced challenges. Research from Keeper Security finds...









