
Baidu AI Presents an End-to-End Self-Reasoning Framework to Improve the Reliability and Traceability of RAG Systems
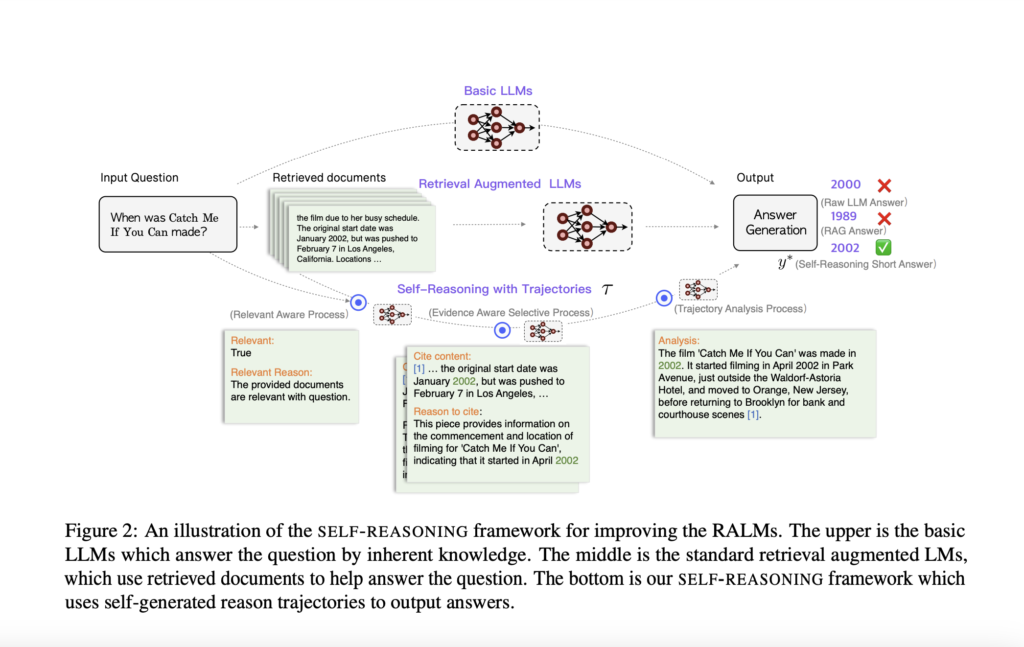
The Retrieval-Augmented Language Model (RALM) enhances LLMs by integrating external knowledge during inference, which reduces factual inaccuracies. Despite this, RALMs face challenges in reliability and traceability. Noisy retrieval can lead to unhelpful or incorrect responses, and a lack of proper citations complicates verifying the model’s outputs. Efforts to improve retrieval robustness include using natural language inference and document summarization models, which add complexity and cost. Optimizing and selecting these auxiliary models remains a significant challenge for effective implementation.
Researchers from Baidu Inc., China, propose a self-reasoning framework to enhance the reliability and traceability of RALMs. This framework generates self-reasoning trajectories through three processes: a relevance-aware process, an evidence-aware selective process, and a trajectory analysis process. It aims to improve response accuracy by teaching the model to reason with retrieved documents. Evaluated on four public datasets, this method outperforms existing models and matches GPT-4 performance using only 2,000 training samples. The framework enhances interpretability and traceability without needing external models.
Many studies have aimed to boost LLMs by integrating external information. Approaches include pre-training with retrieved passages, incorporating citations, and using end-to-end systems that retrieve evidence and generate answers without changing model weights. Some methods dynamically instruct or fine-tune LLMs to use retrieval tools, while others focus on improving factual accuracy through retrieval and editing. Techniques such as filtering irrelevant documents, document compression, and error correction have been explored to enhance robustness. The approach, in contrast, identifies key sentences and cites relevant documents within an end-to-end framework, avoiding the need for external models and offering efficiency without relying on special tokens or extensive training samples.
The problem of retrieval-augmented generation with self-reasoning involves defining the process where an LLM generates answers based on reasoning trajectories. Given a query and a document corpus, the model produces answers composed of statements and tokens, with each statement citing relevant documents. The approach involves training the LLM to generate reasoning trajectories and answers in one pass. The process is divided into three stages: evaluating document relevance, selecting and citing key sentences, and analyzing reasoning to produce a final answer. Data is generated and quality-controlled using automated tools and filtering methods to ensure accuracy before training the model on this augmented data.

Extensive experiments were conducted on two short-form QA datasets, one long-form QA dataset, and one fact verification dataset to evaluate the SELF-REASONING framework. The framework’s effectiveness was assessed using various off-the-shelf retrievers and metrics tailored to each task, including accuracy, exact match recall, citation recall, and precision. Compared to basic and retrieval-augmented LLMs, the SELF-REASONING approach demonstrated superior performance, particularly in long-form QA and fact verification tasks. It outperformed most baseline models, including those requiring additional training data or external tools, while achieving high citation recall and accuracy with fewer training samples and reduced resource consumption.
An ablation study assessed the contributions of each component in the SELF-REASONING framework across short-form QA and fact verification datasets. Results showed that omitting the Relevant-Aware Process (RAP), Evidence-Aware Selective Process (EAP), or Trajectory Analysis Process (TAP) significantly reduced performance, highlighting the importance of each component. The framework demonstrated robustness to noisy and shuffled retrieved documents, outperforming other models in such conditions. Human citation analysis showed that the framework’s citation quality is well-aligned with automatic evaluations, often with better scores. The findings underscore the framework’s effectiveness in enhancing LLM performance on knowledge-intensive tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.










