AWS Researchers Propose LEDEX: A Machine Learning Training Framework that Significantly Improves the Self-Debugging Capability of LLMs
Code generation using Large Language Models (LLMs) has emerged as a critical research area, but generating accurate code for complex problems in a single attempt remains a significant challenge. Even skilled human developers often require multiple iterations of trial-and-error debugging to solve difficult programming problems. While LLMs have demonstrated impressive code generation capabilities, their self-debugging ability to analyze incorrect code and make necessary corrections is still limited. This limitation is evident in open-source models like StarCoder and CodeLlama, which show significantly lower self-refinement performance compared to models like GPT-3.5-Turbo.
Existing approaches to improve code generation and debugging capabilities in LLMs have followed several distinct paths. LLMs have shown significant success across various code-related tasks, including code generation, bug fixing, program testing, and fuzzing. These models use extensive pre-training on vast datasets to understand patterns and generate contextually relevant code. However, most existing work has primarily focused on single-round generation rather than iterative improvement. Other methods like ILF, CYCLE, and Self-Edit have explored supervised fine-tuning approaches while solutions like OpenCodeInterpreter and EURUS have attempted to create high-quality multi-turn interaction datasets using advanced models for fine-tuning purposes.
Researchers from Purdue University, AWS AI Labs, and the University of Virginia have proposed LEDEX (learning to self-debug and explain code), a novel training framework designed to enhance LLMs’ self-debugging capabilities. The framework builds on the observation that a sequential process of explaining incorrect code followed by refinement enables LLMs to analyze and improve faulty code in a better way. LEDEX implements an automated pipeline to collect high-quality datasets for code explanation, and refinement. Moreover, it combines supervised fine-tuning (SFT) and reinforcement learning (RL) approaches, utilizing successful and failed trajectories with a specialized reward system that evaluates code explanation and refinement quality.
LEDEX employs a comprehensive architecture containing data collection, verification, and multi-stage training processes. The framework begins by collecting code explanation and refinement datasets through queries to pre-trained or instruction-tuned models. These responses undergo rigorous execution-based verification to filter and maintain only high-quality explanation and refinement data. The collected dataset then serves as input for supervised fine-tuning which significantly enhances the model’s capabilities in bug explanation and code refinement. LEDEX uses programming problems from MBPP, APPS, and CodeContests to train data. To expand the dataset of incorrect solutions, the framework prompts pre-trained LLMs like StarCoder and CodeLlama with 3-shot examples to generate 20 solutions per problem.

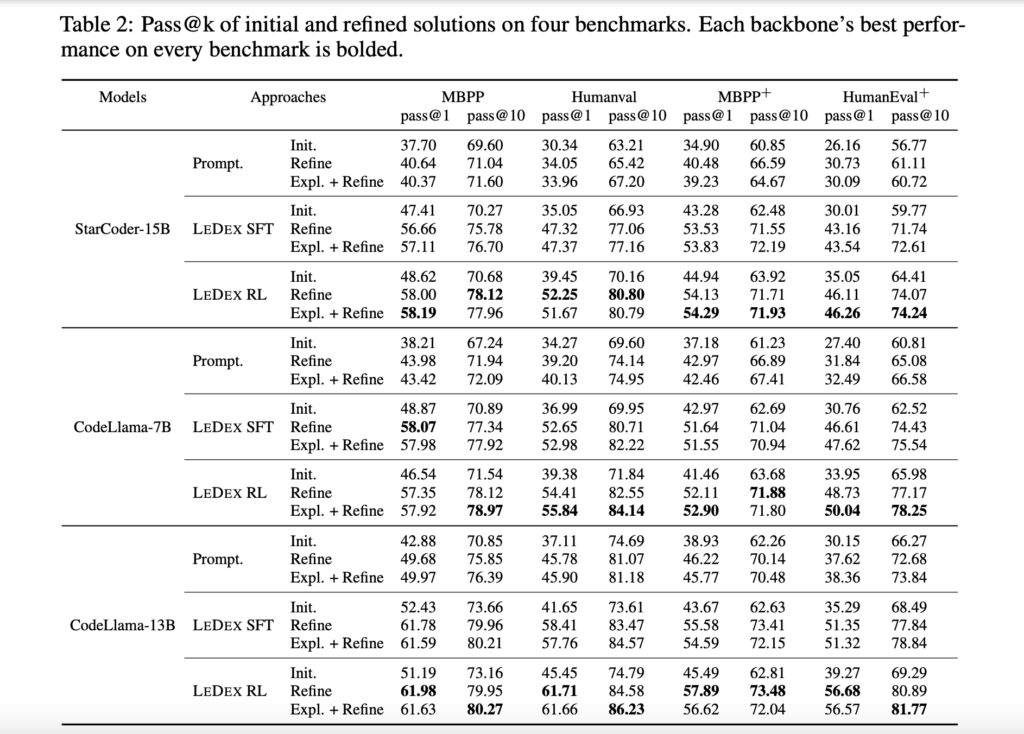
LEDEX is evaluated using three model backbones: StarCoder-15B, CodeLlama-7B, and CodeLlama-13B, with initial training data collected from GPT-3.5-Turbo. The SFT phase shows significant improvements, achieving up to a 15.92% increase in pass@1 and 9.30% in pass@10 metrics across four benchmark datasets. The subsequent RL phase further enhances performance with additional improvements of up to 3.54% in pass@1 and 2.55% in pass@10. Notably, LEDEX’s model-agnostic nature is shown through experiments with CodeLlama-7B, which achieve substantial improvements (8.25% in pass@1 and 2.14% in pass@10) even when trained on data collected from CodeLlama-34B or itself, proving its effectiveness independent of GPT-3.5-Turbo.
In conclusion, researchers introduced LEDEX, a comprehensive and scalable framework that combines automated data collection, verification processes, SFT, and RL with innovative reward designs to significantly improve LLMs’ ability to identify and correct code errors. The framework’s model-agnostic nature is evidenced by its successful implementation with GPT-3.5-Turbo and CodeLlama, while its rigorous data verification process ensures the quality of code explanations and refinements. Human evaluations further validate the framework’s effectiveness, confirming that LEDEX-trained models produce superior code explanations that effectively assist developers in understanding and resolving code issues.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.