
Apple Researchers Propose LazyLLM: A Novel AI Technique for Efficient LLM Inference in Particular under Long Context Scenarios
Large Language Models (LLMs) have made a significant leap in recent years, but their inference process faces challenges, particularly in the prefilling stage. The primary issue lies in the time-to-first-token (TTFT), which can be slow for long prompts due to the deep and wide architecture of state-of-the-art transformer-based LLMs. This slowdown occurs because the cost of computing attention increases quadratically with the number of tokens in the prompts. For example, Llama 2 with 7 billion parameters requires 21 times more time for TTFT compared to each subsequent decoding step, accounting for approximately 23% of the total generation time on the LongBench benchmark. Optimizing TTFT has become a critical path toward efficient LLM inference.
Prior studies have explored various approaches to address the challenges of efficient long-context inference and TTFT optimization in LLMs. Some methods focus on modifying transformer architectures, such as replacing standard self-attention with local windowed attention or using locality-sensitive hashing. However, these require significant model changes and retraining. Other techniques optimize the KV cache to accelerate decoding steps but don’t address TTFT. Token pruning approaches, which selectively remove less important tokens during inference, have shown promise in sentence classification tasks. Examples include Learned Token Pruning and width-wise computation reduction. However, these methods were designed for single-iteration processing tasks and need adaptation for generative LLMs. Each approach has limitations, prompting the need for more versatile solutions that can improve TTFT without extensive model modifications.
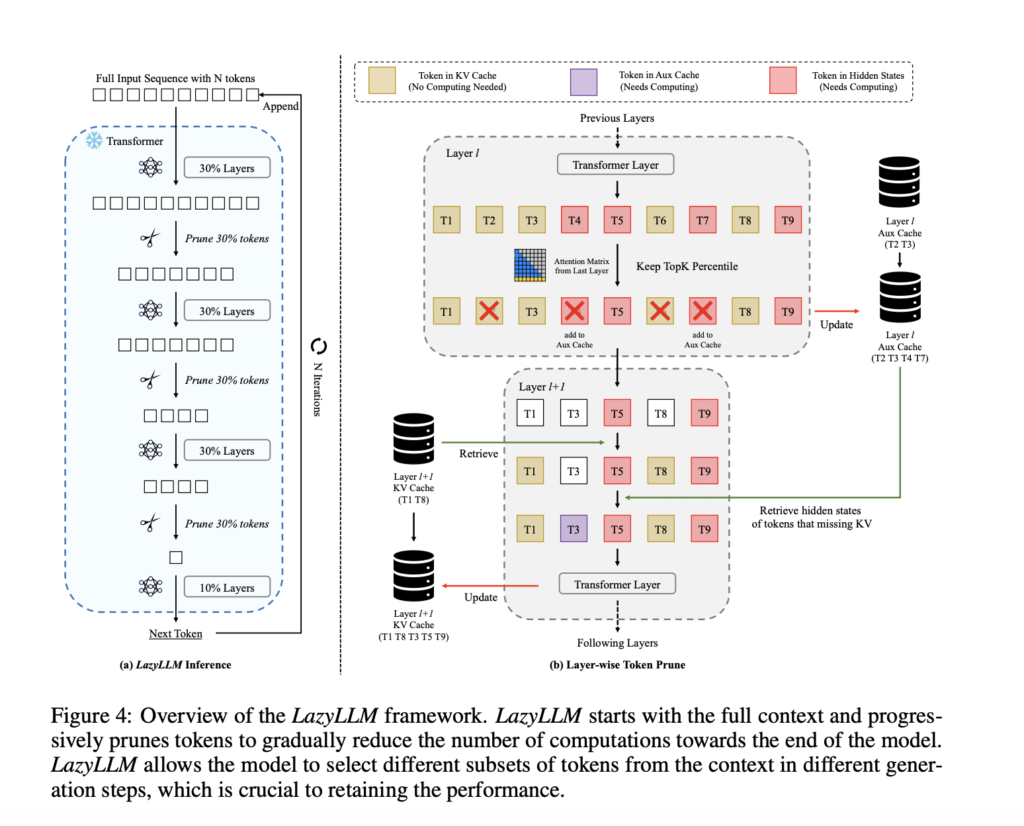
Researchers from Apple and Meta AI propose LazyLLM, a unique technique to accelerate LLM prefilling by selectively computing the KV cache for important tokens and deferring less crucial ones. It uses attention scores from previous layers to assess token importance and prune progressively. Unlike permanent prompt compression, LazyLLM can revive pruned tokens to maintain accuracy. An Aux Cache mechanism stores pruned tokens’ hidden states, ensuring efficient revival and preventing performance degradation. LazyLLM offers three key advantages: universality (compatible with any transformer-based LLM), training-free implementation, and effectiveness across various language tasks. This method improves inference speed in both prefilling and decoding stages without requiring model modifications or fine-tuning.
The LazyLLM framework is designed to optimize LLM inference through progressive token pruning. The method starts with the full context and gradually reduces computations towards the end of the model by pruning less important tokens. Unlike static pruning, LazyLLM allows the dynamic selection of token subsets in different generation steps, crucial for maintaining performance.

This framework employs layer-wise token pruning in each generation step, using attention maps to determine token importance. It calculates a confidence score for each token and prunes those below a certain percentile. This approach is applied progressively, keeping more tokens in earlier layers and reducing them towards the end of the transformer.
To overcome the challenges in extending pruning to decoding steps, LazyLLM introduces an Aux Cache mechanism. This cache stores hidden states of pruned tokens, allowing efficient retrieval without recomputation. During decoding, the model first accesses the KV cache for existing tokens and retrieves hidden states from the Aux Cache for pruned tokens. Also, this implementation ensures each token is computed at most once per transformer layer, guaranteeing that LazyLLM’s worst-case runtime is not slower than the baseline. The method’s dynamic nature and efficient caching mechanism contribute to its effectiveness in optimizing both the prefilling and decoding stages of LLM inference.
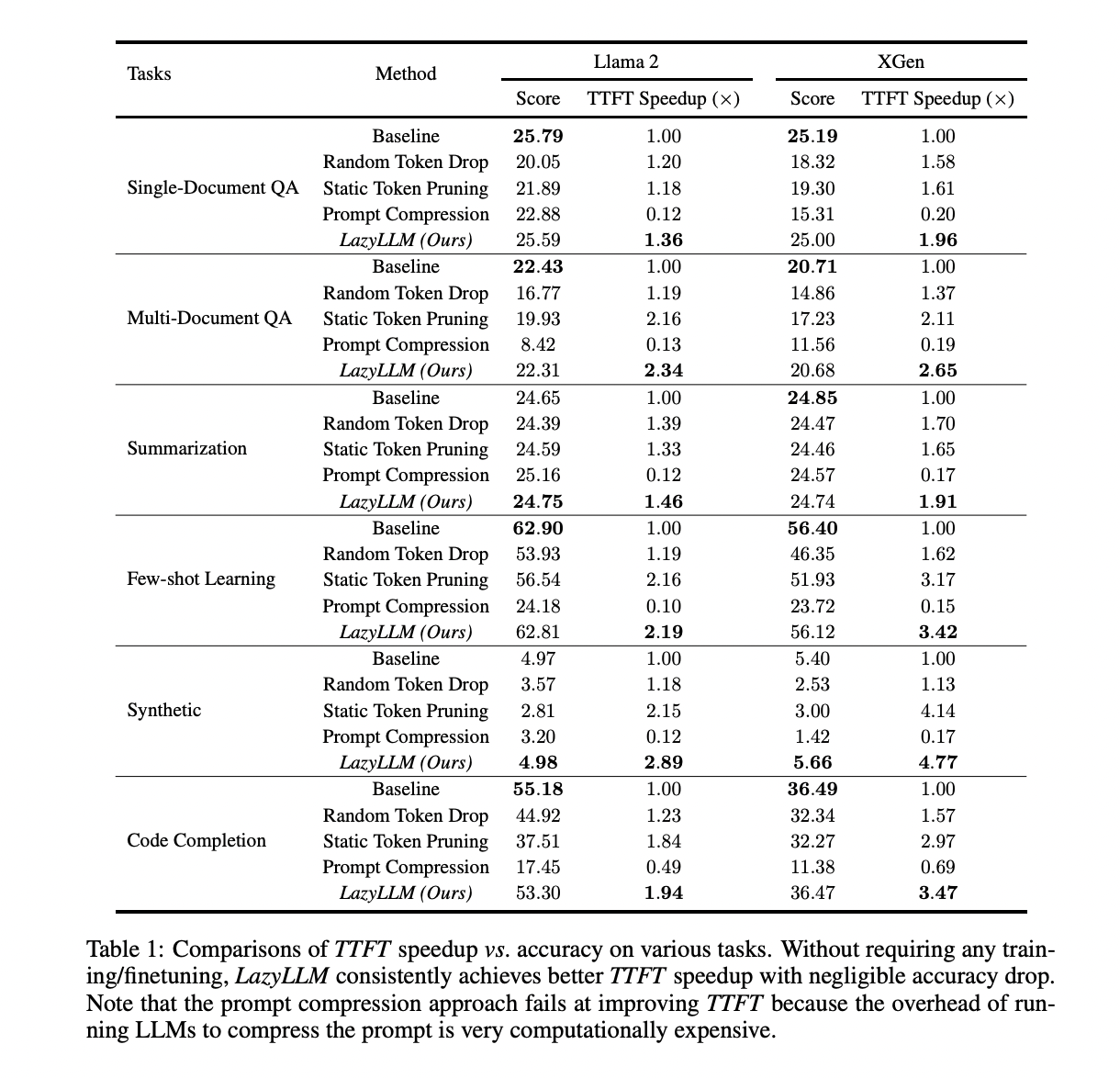
LazyLLM demonstrates significant improvements in LLM inference efficiency across various language tasks. It achieves substantial TTFT speedups (up to 2.89x for Llama 2 and 4.77x for XGen) while maintaining accuracy close to baseline levels. The method outperforms other approaches like random token drop, static pruning, and prompt compression in speed-accuracy trade-offs. LazyLLM’s effectiveness spans multiple tasks, including QA, summarization, and code completion. It often computes less than 100% of prompt tokens, leading to reduced overall computation and improved generation speeds. The progressive pruning strategy, informed by layer-wise analysis, contributes to its superior performance. These results highlight LazyLLM’s capacity to optimize LLM inference without compromising accuracy.
LazyLLM, an innovative technique for efficient LLM inference, particularly in long context scenarios, selectively computes KV for important tokens and defers computation of less relevant ones. Extensive evaluation across various tasks demonstrates that LazyLLM significantly reduces TTFT while maintaining performance. A key advantage is its seamless integration with existing transformer-based LLMs, improving inference speed without fine-tuning. By dynamically prioritizing token computation based on relevance, LazyLLM offers a practical solution to enhance LLM efficiency, addressing the growing demand for faster and more resource-efficient language models in diverse applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.









