AutoRAG: An Automated Tool for Optimizing Retrieval-Augmented Generation Pipelines
Retrieval-Augmented Generation (RAG) is a framework that enhances language models by combining two main components: Retriever and Generator. A RAG pipeline combines the retriever and generator in an iterative process and is widely used in open-domain question-answer, knowledge-based chatbots, and specialized information retrieval tasks where the accuracy and relevance of real-world data are crucial. Despite the availability of various RAG pipelines and modules, it is difficult to select which pipeline is great for own data and own use cases”. Moreover, making and evaluating all RAG modules is very time-consuming and hard to do, but without it, it is difficult to know which RAG pipeline is the best for the self-use case.
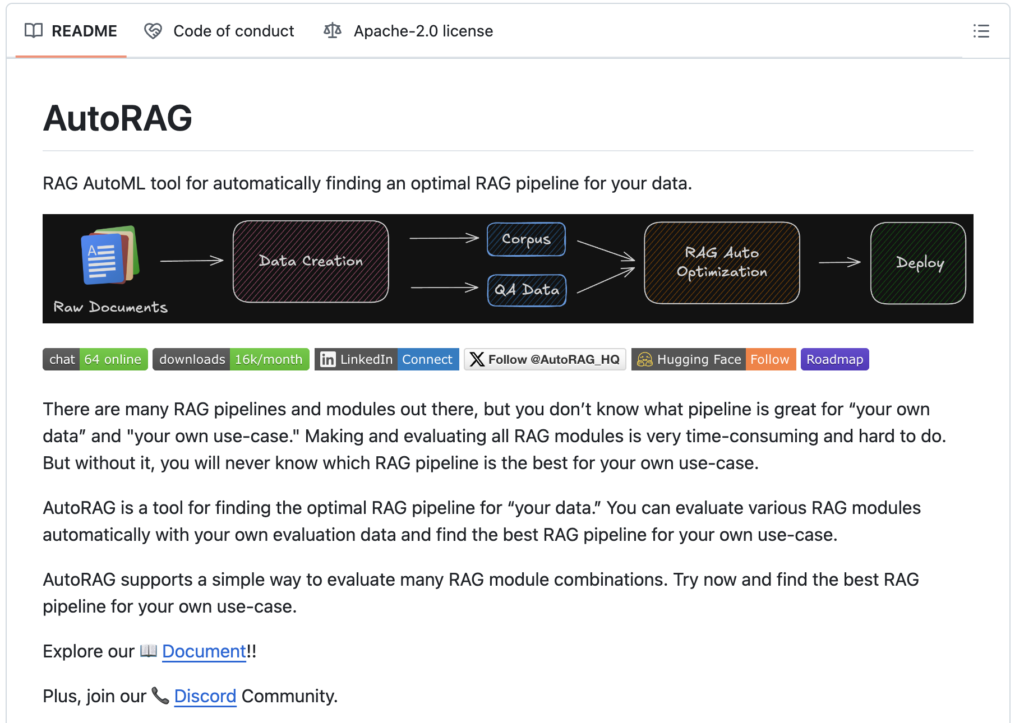
AutoRAG ( ) is a tool for finding optimal RAG pipeline for “self data.” It helps to automatically evaluate various RAG modules with self-evaluation data and find the best RAG pipeline for self-use cases. AutoRAG supports:
Data Creation: Create RAG evaluation data with raw documents.
Optimization: Automatically run experiments to find the best RAG pipeline for the data.

Deployment: Deploy the best RAG pipeline with a single YAML file and support the Flask server as well.
In optimization for a RAG pipeline, a node represents a specific function, with the result of each node passed to the following node. The core nodes for an effective RAG pipeline are retrieval, prompt maker, and generator, with additional nodes available to enhance performance. AutoRAG achieves optimization by creating all possible combinations of modules and parameters within each node, executing the pipeline with each configuration, and selecting the optimal result according to predefined strategies. The chosen result from the preceding node then becomes the input for the next, meaning each node operates based on the best result from its predecessor. Each node functions independently of how the input result is produced, similar to a Markov Chain, where only the previous state is required to generate the next state, without knowledge of the entire pipeline or preceding steps.

RAG models need data for evaluation but in most cases, there is little or no suitable data available. However, with the advent of large language models (LLMs), generating synthetic data has emerged as an effective solution to this challenge. The following guide outlines how to use LLMs to create data in a format compatible with AutoRAG:
Parsing: Set the YAML file and start parsing. Here, raw documents can be parsed with just a few lines of code to prepare the data.
Chunking: A single corpus is used to create initial QA pairs, after which the remaining corpus is mapped to QA data.
QA Creation: Each corpus needs a corresponding QA dataset if multiple corpora are generated through different chunking methods.
QA-Corpus Mapping: For multiple corpora, the remaining corpus data can be mapped to the QA dataset. To optimize chunking, RAG performance can be evaluated using various corpus data.
Certain nodes, such as query_expansion or prompt_maker, cannot be evaluated directly. To evaluate these nodes, it is necessary to establish ground truth values, such as the “ground truth of expanded query” or “ground truth of prompt.” In this method, documents are retrieved during the evaluation process using the designated modules, and the query_expansion node is evaluated based on these retrieved documents. A similar approach applies to the prompt_maker and generation nodes, where the prompt_maker node is evaluated using the results from the generation node. AutoRAG is currently in its alpha phase with numerous optimization possibilities for future development.
In conclusion, AutoRAG is an automated tool designed to identify the optimal RAG pipeline for specific datasets and use cases. It automates the evaluation of various RAG modules using self-evaluation data, offering support for data creation, optimization, and deployment. Moreover, AutoRAG structures the pipeline into interconnected nodes (retrieval, prompt maker, and generator) and evaluates combinations of modules and parameters to find the best configuration. Synthetic data from LLMs enhances evaluation. Currently in its alpha phase, AutoRAG offers significant potential for further optimization and development in RAG pipeline selection and deployment.
Check out the GitHub Repo. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.