Revolutionizing Fine-Tuned Small Language Model Deployments: Introducing Predibase’s Next-Gen Inference Engine
Predibase announces the Predibase Inference Engine, their new infrastructure offering designed to be the best platform for serving fine-tuned small language models (SLMs). The Predibase Inference Engine dramatically improves SLM deployments by making them faster, easily scalable, and more cost-effective for enterprises grappling with the complexities of productionizing AI. Built on Predibase’s innovations–Turbo LoRA and LoRA eXchange (LoRAX)–the Predibase Inference Engine is designed from the ground up to offer a best-in-class experience for serving fine-tuned SLMs.
The need for such an innovation is clear. As AI becomes more entrenched in the fabric of enterprise operations, the challenges associated with deploying and scaling SLMs have grown increasingly daunting. Homegrown infrastructure is often ill-equipped to handle the dynamic demands of high-volume AI workloads, leading to inflated costs, diminished performance, and operational bottlenecks. The Predibase Inference Engine addresses these challenges head-on, offering a tailor-made solution for enterprise AI deployments.
Join Predibase webinar on October 29th to learn more about the Predibase Inference Engine!
The Key Challenges in Deploying LLMs at Scale
As businesses continue to integrate AI into their core operations and need to prove ROI, the demand for efficient, scalable solutions has skyrocketed. The deployment of LLMs, and fine-tuned SLMs in particular, has become a critical component of successful AI initiatives but presents significant challenges at scale:

Performance Bottlenecks: Most cloud providers’ entry-level GPUs struggle with production use cases, especially those with spiky or variable workloads, resulting in slow response times and a diminished customer experience. Additionally, scaling LLM deployments to meet peak demand without incurring prohibitive costs or performance degradation is a significant challenge due to the lack of GPU autoscaling capabilities in many cloud environments.
Engineering Complexity: Adopting open-source models for production use requires enterprises to manage the entire serving infrastructure themselves—a high-stakes, resource-intensive proposition. This adds significant engineering complexity, demanding specialized expertise and forcing teams to devote substantial resources to ensure reliable performance and scalability in production environments.
High Infrastructure Costs: High-performing GPUs like the NVIDIA H100 and A100 are in high demand and often have limited availability from cloud providers, leading to potential shortages. These GPUs are typically offered in “always-on” deployment models, which ensure availability but can be costly due to continuous billing, regardless of actual usage.
These challenges underscore the need for a solution like the Predibase Inference Engine, which is designed to streamline the deployment process and provide a scalable, cost-effective infrastructure for managing SLMs.
Technical Breakthroughs in the Predibase Inference Engine
At the heart of the Predibase Inference Engine are a set of innovative features that collectively enhance the deployment of SLMs:
LoRAX: LoRA eXchange (LoRAX) allows for the serving of hundreds of fine-tuned SLMs from a single GPU. This capability significantly reduces infrastructure costs by minimizing the number of GPUs needed for deployment. It’s particularly beneficial for businesses that need to deploy various specialized models without the overhead of dedicating a GPU to each model. Learn more.
Turbo LoRA: Turbo LoRA is our parameter-efficient fine-tuning method that accelerates throughput by 2-3 times while rivaling or exceeding GPT-4 in terms of response quality. These throughput improvements greatly reduce inference costs and latency, even for high-volume use cases.
FP8 Quantization: Implementing FP8 quantization can reduce the memory footprint of deploying a fine-tuned SLM by 50%, leading to nearly 2x further improvements in throughput. This optimization not only improves performance but also enhances the cost-efficiency of deployments, allowing for up to 2x more simultaneous requests on the same number of GPUs.
GPU Autoscaling: Predibase SaaS deployments can dynamically adjust GPU resources based on real-time demand. This flexibility ensures that resources are efficiently utilized, reducing waste and cost during periods of fluctuating demand.
These technical innovations are crucial for enterprises looking to deploy AI solutions that are both powerful and economical. By addressing the core challenges associated with traditional model serving, the Predibase Inference Engine sets a new standard for efficiency and scalability in AI deployments.
LoRA eXchange: Scale 100+ Fine-Tuned LLMs Efficiently on a Single GPU
LoRAX is a cutting-edge serving infrastructure designed to address the challenges of deploying multiple fine-tuned SLMs efficiently. Unlike traditional methods that require each fine-tuned model to run on dedicated GPU resources, LoRAX allows organizations to serve hundreds of fine-tuned SLMs on a single GPU, drastically reducing costs. By utilizing dynamic adapter loading, tiered weight caching, and multi-adapter batching, LoRAX optimizes GPU memory usage and maintains high throughput for concurrent requests. This innovative infrastructure enables cost-effective deployment of fine-tuned SLMs, making it easier for enterprises to scale AI models specialized to their unique tasks.
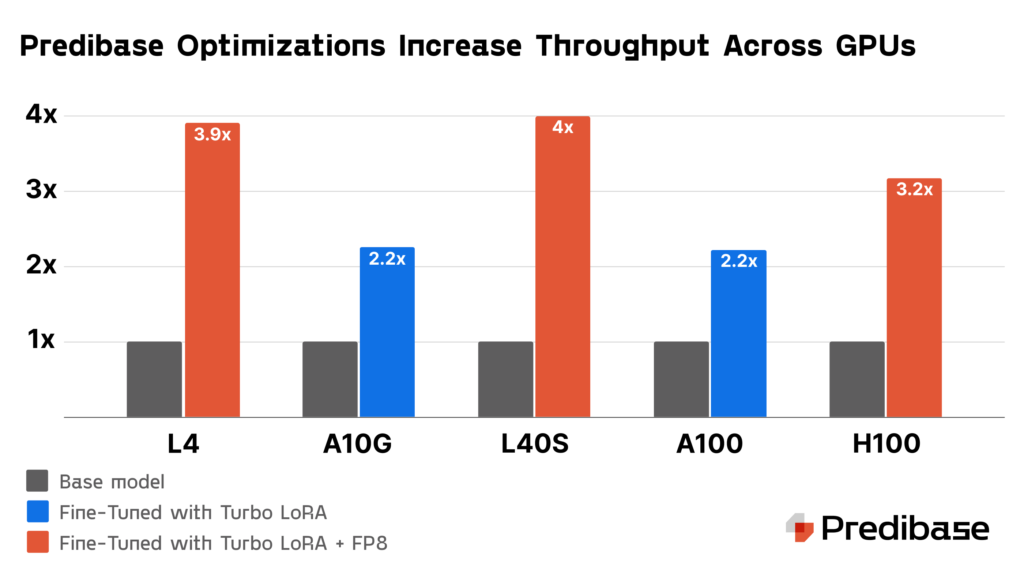
Get more out of your GPU: 4x speed improvements for SLMs with Turbo LoRA and FP8
Optimizing SLM inference is crucial for scaling AI deployments, and two key techniques are driving major throughput performance gains. Turbo LoRA boosts throughput by 2-3x through speculative decoding, making it possible to predict multiple tokens in one step without sacrificing output quality. Additionally, FP8 quantization further increases GPU throughput, enabling much more cost effective deployments when using modern hardware like NVIDIA L40S GPUs.
Turbo LoRA Increases Throughput by 2-3x
Turbo LoRA combines Low Rank Adaptation (LoRA) and speculative decoding to enhance the performance of SLM inference. LoRA improves response quality by adding new parameters tailored to specific tasks, but it typically slows down token generation due to the extra computational steps. Turbo LoRA addresses this by enabling the model to predict multiple tokens in one step, significantly increasing throughput by 2-3 times compared to base models without compromising output quality.
Turbo LoRA is particularly effective because it adapts to all types of GPUs, including high-performing models like H100s and entry level models like the A10g. This universal compatibility ensures that organizations can deploy Turbo LoRA across different hardware setups (whether in Predibase’s cloud or their VPC environment) without needing specific adjustments for each GPU type. This makes Turbo LoRA a cost-effective solution for enhancing the performance of SLMs across a wide range of computing environments.
In addition, Turbo LoRA achieves these benefits all through a single model whereas the majority of speculative decoding implementations use a draft model in addition to their main model. This further reduces the GPU requirements and network overhead.
Further Increase Throughput with FP8
FP8 quantization is a technique that reduces the precision of a model’s data format from a standard floating-point representation, such as FP16, to an 8-bit floating-point format. This compression reduces the model’s memory footprint by up to 50%, allowing it to process data more efficiently and increasing throughput on GPUs. The smaller size means that less memory is required to store weights and perform matrix multiplications, which consequently can nearly double the throughput of a given GPU.
Beyond just performance enhancements, FP8 quantization also impacts the cost-efficiency of deploying SLMs. By increasing the number of concurrent requests a GPU can handle, organizations can meet their performance SLAs with fewer compute resources. While only the latest generation of NVIDIA GPUs support FP8, applying FP8 to L40S GPUs–now more readily available in Amazon EC2–increases throughput to outperform an A100 GPU while costing roughly 33% less.
Optimized GPU Scaling for Performance and Cost Efficiency
GPU autoscaling is a critical feature for managing AI workloads, ensuring that resources are dynamically adjusted based on real-time demand. Our Inference Engine’s ability to scale GPU resources as needed helps enterprises optimize usage, reducing costs by only scaling up when demand increases and scaling down during quieter periods. This flexibility allows organizations to maintain high-performance AI operations without over-provisioning resources.

For applications that require consistent performance, our platform offers the option to reserve GPU capacity, guaranteeing availability during peak loads. This is particularly valuable for use cases where response times are crucial, ensuring that even during traffic spikes, AI models perform without interruptions or delays. Reserved capacity ensures enterprises meet their performance SLAs without unnecessary over-allocation of resources.
Additionally, the Inference Engine minimizes cold start times by rapidly scaling resources, reducing delays in startup and ensuring quick adjustments to sudden increases in traffic. This feature enhances the responsiveness of the system, allowing organizations to handle unpredictable traffic surges efficiently and without compromising on performance.

In addition to optimizing performance, GPU autoscaling significantly reduces deployment costs. Unlike traditional “always-on” GPU deployments, which incur continuous expenses regardless of actual usage, autoscaling ensures resources are allocated only when needed. In the example above, a standard always-on deployment for an enterprise workload would cost over $213,000 per year, while an autoscaling deployment reduces that to less than $155,000 annually—offering a savings of nearly 30%. (It’s important to note that both deployment configurations cost less than half as much as using fine-tuned GPT-4o-mini.) By dynamically adjusting GPU resources based on real-time demand, enterprises can achieve high performance without the burden of overpaying for idle infrastructure, making AI deployments far more cost-effective.
Enterprise readiness
Designing AI infrastructure for enterprise applications is complex, with many critical details to manage if you’re building your own. From security compliance to ensuring high availability across regions, enterprise-scale deployments require careful planning. Teams must balance performance, scalability, and cost-efficiency while integrating with existing IT systems.
Predibase’s Inference Engine simplifies this by offering enterprise-ready solutions that address these challenges, including VPC integration, multi-region high availability, and real-time deployment insights. These features help enterprises like Convirza deploy and manage AI workloads at scale without the operational burden of building and maintaining infrastructure themselves.
“At Convirza, our workload can be extremely variable, with spikes that require scaling up to double-digit A100 GPUs to maintain performance. The Predibase Inference Engine and LoRAX allow us to efficiently serve 60 adapters while consistently achieving an average response time of under two seconds,” said Giuseppe Romagnuolo, VP of AI at Convirza. “Predibase provides the reliability we need for these high-volume workloads. The thought of building and maintaining this infrastructure on our own is daunting—thankfully, with Predibase, we don’t have to.”
Our cloud or yours: Virtual Private Clouds
The Predibase Inference Engine is available in our cloud or yours. Enterprises can choose between deploying within their own private cloud infrastructure or utilizing Predibase’s fully managed SaaS platform. This flexibility ensures seamless integration with existing enterprise IT policies, security protocols, and compliance requirements. Whether companies prefer to keep their data and models entirely within their Virtual Private Cloud (VPC) for enhanced security and to take advantage of cloud provider spend commitments or leverage Predibase’s SaaS for added flexibility, the platform adapts to meet diverse enterprise needs.
Multi-Region High Availability
The Inference Engine’s multi-region deployment feature ensures that enterprises can maintain uninterrupted service, even in the event of regional outages or disruptions. In the event of a disruption, the platform automatically reroutes traffic to a functioning region and spins up additional GPUs to handle the increased demand. This rapid scaling of resources minimizes downtime and ensures that enterprises can maintain their service-level agreements (SLAs) without compromising performance or reliability.

By dynamically provisioning extra GPUs in the failover region, the Inference Engine provides immediate capacity to support critical AI workloads, allowing businesses to continue operating smoothly even in the face of unexpected failures. This combination of multi-region redundancy and autoscaling guarantees that enterprises can deliver consistent, high-performance services to their users, no matter the circumstances.
Maximizing Efficiency with Real-Time Deployment Insights
In addition to the Inference Engine’s powerful autoscaling and multi-region capabilities, Predibase’s Deployment Health Analytics provide essential real-time insights for monitoring and optimizing your deployments. This tool tracks critical metrics like request volume, throughput, GPU utilization, and queue duration, giving you a comprehensive view of how well your infrastructure is performing. By using these insights, enterprises can easily balance performance with cost efficiency, scaling GPU resources up or down as needed to meet fluctuating demand while avoiding over-provisioning.

With customizable autoscaling thresholds, Deployment Health Analytics allows you to fine-tune your strategy based on specific operational needs. Whether it’s ensuring that GPUs are efficiently utilized during traffic spikes or scaling down resources to minimize costs, these analytics empower businesses to maintain high-performance deployments that run smoothly at all times. For more details on optimizing your deployment strategy, check out the full blog post.
Why Choose Predibase?
Predibase is the leading platform for enterprises serving fine-tuned LLMs, offering unmatched infrastructure designed to meet the specific needs of modern AI workloads. Our Inference Engine is built for maximum performance, scalability, and security, ensuring enterprises can deploy fine-tuned models with confidence. With built-in compliance and a focus on cost-effective, reliable model serving, Predibase is the top choice for companies looking to serve fine-tuned LLMs at scale while maintaining enterprise-grade security and efficiency.
If you’re ready to take your LLM deployments to the next level, visit Predibase.com to learn more about the Predibase Inference Engine, or try it for free to see firsthand how our solutions can transform your AI operations.
Thanks to the Predibase team for the thought leadership/ Resources for this article. The Predibase AI team has supported us in this content/article.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.