Cerebras Introduces the World’s Fastest AI Inference for Generative AI: Redefining Speed, Accuracy, and Efficiency for Next-Generation AI Applications Across Multiple Industries
Cerebras Systems has set a new benchmark in artificial intelligence (AI) with the launch of its groundbreaking AI inference solution. The announcement offers unprecedented speed and efficiency in processing large language models (LLMs). This new solution, called Cerebras Inference, is designed to meet AI applications’ challenging and increasing demands, particularly those requiring real-time responses and complex multi-step tasks.
Unmatched Speed and Efficiency
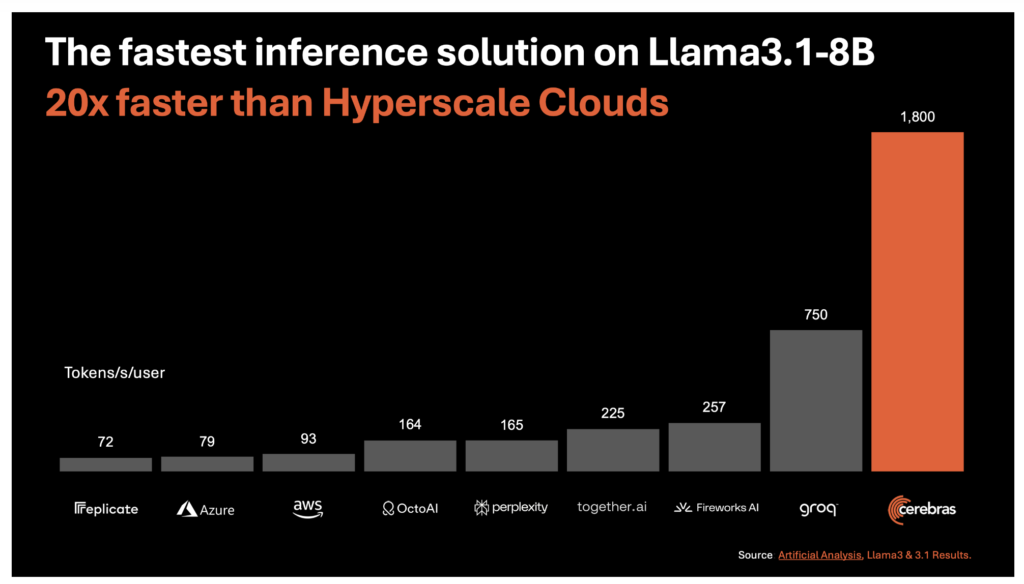
At the core of Cerebras Inference is the third-generation Wafer Scale Engine (WSE-3), which powers the fastest AI inference solution currently available. This technology delivers a remarkable 1,800 tokens per second for Llama3.1 8B and 450 tokens per second for Llama3.1 70B models. These speeds are approximately 20 times faster than traditional GPU-based solutions in hyperscale cloud environments. This performance leap is not just about raw speed; it also comes at a fraction of the cost, with pricing set at just 10 cents per million tokens for the Llama 3.1 8B model and 60 cents per million tokens for the Llama 3.1 70B model.
The significance of this achievement cannot be overstated. Inference, which involves running AI models to make predictions or generate text, is a critical component of many AI applications. Faster inference means that applications can provide real-time responses, making them more interactive and effective. This is particularly important for applications that rely on large language models, such as chatbots, virtual assistants, and AI-driven search engines.

Addressing the Memory Bandwidth Challenge
One of the major challenges in AI inference is the need for vast memory bandwidth. Traditional GPU-based systems often need help, requiring large amounts of memory to process each token in a language model. For example, the Llama3.1-70B model, which has 70 billion parameters, requires 140GB of memory to process a single token. To generate just ten tokens per second, a GPU would need 1.4 TB/s of memory bandwidth, which far exceeds the capabilities of current GPU systems.
Cerebras has overcome this bottleneck by directly integrating a massive 44GB of SRAM onto the WSE-3 chip, eliminating the need for external memory and significantly increasing memory bandwidth. The WSE-3 offers an astounding 21 petabytes per second of aggregate memory bandwidth, 7,000 times greater than the Nvidia H100 GPU. This breakthrough allows Cerebras Inference to easily handle large models, providing faster and more accurate inference.
Maintaining Accuracy with 16-bit Precision
Another critical aspect of Cerebras Inference is its commitment to accuracy. Unlike some competitors who reduce weight precision to 8-bit to achieve faster speeds, Cerebras retains the original 16-bit precision throughout the inference process. This ensures that the model outputs are as accurate as possible, which is crucial for tasks that require high levels of precision, such as mathematical computations and complex reasoning tasks. According to Cerebras, their 16-bit models score up to 5% higher in accuracy than their 8-bit counterparts, making them a superior choice for developers who need both speed and reliability.
Strategic Partnerships and Future Expansion
Cerebras is not just focusing on speed and efficiency but also building a robust ecosystem around its AI inference solution. It has partnered with leading companies in the AI industry, including Docker, LangChain, LlamaIndex, and Weights & Biases, to provide developers with the tools they need to build and deploy AI applications quickly and efficiently. These partnerships are crucial for accelerating AI development and ensuring developers can access the best resources.
Cerebras plans to expand its support for even larger models, such as the Llama3-405B and Mistral Large models. This will cement Cerebras Inference as the go-to solution for developers working on cutting-edge AI applications. The company also offers its inference service across three tiers: Free, Developer, and Enterprise, catering to various users from individual developers to large enterprises.
The Impact on AI Applications
The implications of Cerebras Inference’s high-speed performance extend far beyond traditional AI applications. By dramatically reducing processing times, Cerebras enables more complex AI workflows and enhances real-time intelligence in LLMs. This could revolutionize industries that rely on AI, from healthcare to finance, by allowing faster and more accurate decision-making processes. For example, faster AI inference could lead to more timely diagnoses and treatment recommendations in the healthcare industry, potentially saving lives. It could enable real-time financial market data analysis, allowing quicker and more informed investment decisions. The possibilities are endless, and Cerebras Inference is poised to unlock new potential in AI applications across various fields.
Conclusion
Cerebras Systems’ launch of the world’s fastest AI inference solution represents a significant leap forward in AI technology. Cerebras Inference is set to redefine what is possible in AI by combining unparalleled speed, efficiency, and accuracy. Innovations like Cerebras Inference will play a crucial role in shaping the future of technology. Whether enabling real-time responses in complex AI applications or supporting the development of next-generation AI models, Cerebras is at the forefront of this exciting journey.
Check out the Details, Blog, and Try it here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Building Performant AI Applications with NVIDIA NIMs and Haystack’
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.