
Google AI Presents Health Acoustic Representations (HeAR): A Bioacoustic Foundation Model Designed to Help Researchers Build Models that Can Listen to Human Sounds and Flag Early Signs of Disease
Health acoustics, encompassing sounds like coughs and breathing, hold valuable health information but must be utilized more in medical machine learning. Existing deep learning models for these acoustics are often task-specific, limiting their generalizability. Non-semantic speech attributes can aid in emotion recognition and detecting diseases like Parkinson’s and Alzheimer’s. Recent advancements in SSL promise to enable models to learn robust, general representations from large, unlabeled data. While SSL has progressed in fields like vision and language, its application to health acoustics remains largely unexplored.
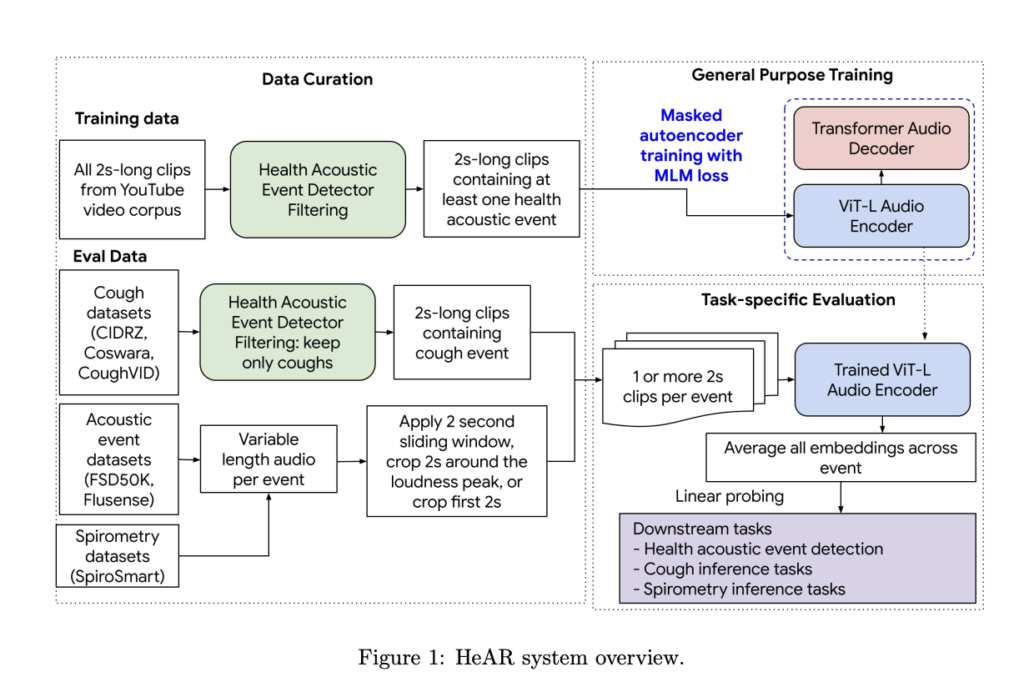
Researchers from Google Research and the Center of Infectious Disease Research in Zambia developed HeAR, a scalable deep-learning system based on SSL. HeAR utilizes masked autoencoders trained on a massive dataset of 313 million two-second audio clips. The model establishes itself as state-of-the-art for health audio embeddings, excelling across 33 health acoustic tasks from 6 datasets. HeAR’s low-dimensional representations, derived from SSL, show strong transferability and generalization to out-of-distribution data, outperforming existing models on functions such as health event detection, cough inference, and spirometry across various datasets.
SSL has become a key approach for developing general representations from large, unannotated datasets. Various SSL methods, such as contrastive (SimCLR, BYOL) and generative (MAE), have advanced, especially in audio processing. Recent progress in SSL-based audio encoders, like Wav2vec 2.0 and AudioMAE, has significantly improved speech representation learning. While non-semantic speech SSL, such as TRILL and FRILL, has seen some development, non-semantic health acoustics still need to be explored. This study introduces a generative SSL framework (MAE) focused on non-semantic health acoustics, aiming to improve generalization in health monitoring and disease detection tasks.
HeAR consists of three main components: data curation (including a health acoustic event detector), general-purpose training for developing an audio encoder, and task-specific evaluation using the trained embeddings. The system encodes two-second audio clips to generate embeddings for downstream tasks. The health acoustic event detector, a CNN, identifies six non-speech health events like coughing and breathing. HeAR is trained on a large dataset (YT-NS) of 313.3 million audio clips using masked autoencoders. It is benchmarked across various health acoustic tasks, demonstrating superior performance compared to state-of-the-art audio encoders like TRILL, FRILL, and CLAP.

HeAR outperformed other models across 33 tasks on six datasets, achieving the highest mean reciprocal rank (0.708) and ranking first in 17 tasks. While CLAP excelled in health acoustic detection (MRR=0.846), HeAR ranked second (MRR=0.538) despite not using FSD50K for training. HeAR’s performance dropped with longer sequences, likely due to its fixed sinusoidal positional encodings. HeAR consistently outperformed baselines in multiple categories for cough inference and spirometry tasks, demonstrating robustness and minimal performance variation across different recording devices, especially in challenging datasets like CIDRZ and SpiroSmart.
The study introduced and assessed the HeAR system, which combines a health acoustic event detector with a generative learning-based audio encoder trained on YT-NS without expert data curation. The system demonstrated strong performance across health acoustic tasks, such as tuberculosis classification from cough sounds and lung function monitoring via smartphone audio. HeAR’s self-supervised learning model proved effective despite limited data, showing robustness across recording devices. However, further validation is needed, especially considering dataset biases and generalization limits. Future research should explore model fine-tuning, on-device processing, and bias mitigation.
Check out the Paper and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.











