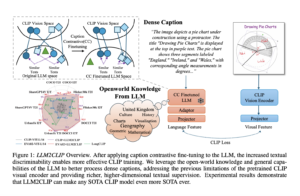
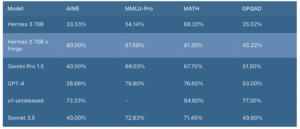
Optimizing Large Language Models for Concise and Accurate Responses through Constrained Chain-of-Thought Prompting

LLMs have shown impressive abilities in handling complex question-answering tasks, supported by advancements in model architectures and training methods. Techniques like chain-of-thought (CoT) prompting have gained popularity for improving the explanation and accuracy of responses by guiding the model through intermediate reasoning steps. However, CoT prompting can result in longer outputs, increasing the time needed for response generation due to the word-by-word decoding process of autoregressive transformers. This creates challenges in maintaining interactive conversations, highlighting the need for metrics to evaluate output conciseness and strategies to reduce overly lengthy reasoning chains.
Researchers from the Department of Excellence in Robotics and AI at Scuola Superiore Sant’Anna and Mediavoice Srl analyzed how output length affects LLM inference time. They proposed new metrics to evaluate conciseness and correctness. They introduced a refined prompt engineering strategy, Constrained-Chain-of-Thought (CCoT), which limits output length to improve accuracy and response time. Experiments with LLaMA2-70b on the GSM8K dataset showed that constraining reasoning to 100 words improved accuracy and reduced output length. The study emphasizes the need for brevity in LLM reasoning and highlights the varying effectiveness of CCoT across different model sizes.
Recent research on LLMs has focused on improving accuracy, often leading to longer and more detailed responses. These extended outputs can cause hallucinations, where the model generates plausible but incorrect information and overly lengthy explanations that obscure key information. Various prompt engineering techniques have been developed to address this, including CoT prompting, which improves reasoning but increases response time. The study introduces metrics to evaluate both conciseness and correctness and proposes a refined CoT approach, CCoT, to control output length while maintaining quality.
The output generation time of LLMs is influenced by factors such as model architecture, preprocessing, decoding, and the prompt used. Longer outputs typically increase response time due to the iterative nature of autoregressive models. Tests on various models (Falcon-7b/40b, Llama2-7b/70b) showed that as output length increases, so does generation time. CoT prompting, which improves response correctness, also lengthens outputs and generation times. To address this, a CCoT approach is proposed, which limits output length while maintaining accuracy, reducing generation time effectively.

The experiments evaluate the effectiveness of the CCoT approach compared to classic CoT, focusing on efficiency, accuracy, and the ability to control output length. Using the GSM8K dataset, various LLMs (e.g., Llama2-70b, Falcon-40b) were tested. Results show that CCoT reduces generation time and can improve or maintain accuracy. The study also introduces new metrics (HCA, SCA, CCA) to assess model performance, considering correctness and conciseness. Larger models like Llama2-70b benefit more from CCoT, while smaller models struggle. CCoT demonstrates improved efficiency and concise accuracy, especially for larger LLMs.
The study emphasizes the importance of conciseness in text generation by LLMs and introduces CCoT as a prompt engineering technique to control output length. Experiments show that larger models like Llama2-70b and Falcon-40b benefit from CCoT, but smaller models need help to meet length constraints. The study also proposes new metrics to evaluate the balance between conciseness and correctness. Future research will explore integrating these metrics into model fine-tuning and examining how conciseness impacts phenomena like hallucinations or incorrect reasoning in LLMs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.