
Open Artificial Knowledge (OAK) Dataset: A Large-Scale Resource for AI Research Derived from Wikipedia’s Main Categories
The rapid advancement of Artificial Intelligence (AI) and Machine Learning (ML) has highlighted the critical need for large, diverse, and high-quality datasets to train and evaluate foundation models. However, acquiring such datasets presents significant challenges, including data scarcity, privacy concerns, and high data collection and annotation costs. Artificial (synthetic) data has emerged as a promising solution to these challenges, offering a way to generate data that mimics real-world patterns and characteristics. The importance of artificial data in AI research has grown substantially due to several factors: scalability, privacy preservation, diversity and representation, and cost-effectiveness. Synthetic data can be generated at scale, address privacy issues, cover a wide range of scenarios to mitigate biases, and provide a more economical alternative to collecting and annotating real-world data.
Recent work in training state-of-the-art language models (LLMs) has increasingly incorporated synthetic datasets, as seen in models like Llama-3. While handcrafted human data has shown significant improvements in supervised fine-tuning (SFT), especially for tasks like code generation and mathematical reasoning, the scarcity and cost of such data have led to increased use of synthetic data. This method utilizes capable LLMs, like the GPT family, to produce high-quality synthetic data. Recent research has highlighted LLMs’ ability to rephrase and boost synthetic data for effective SFT, suggesting continued growth in synthetic data use for improving LLM performance and alignment.
Artificial data generation has several key challenges. These include ensuring diversity and generalization, maintaining quality, preserving privacy, addressing bias, and adhering to ethical and legal considerations. Diversity in artificial data is crucial for model generalization, while quality directly impacts the performance of models trained on it. Privacy concerns must be addressed to prevent revealing sensitive information. Bias in artificial data can arise from underlying algorithms and training data, potentially leading to unfair or inaccurate model predictions. Ethical and legal considerations involve adhering to guidelines and regulations such as GDPR and CCPA. Also, practical challenges include scalability, cost-effectiveness, developing robust evaluation metrics, ensuring factual accuracy, and maintaining and updating synthetic data to reflect current trends and linguistic changes.
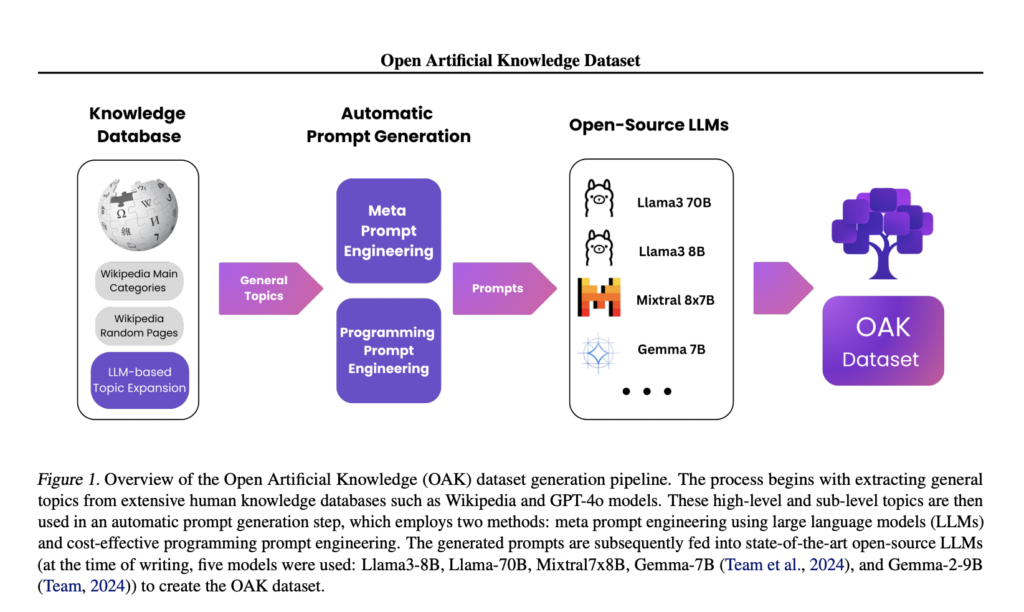
Vadim Borisov and Richard H. Schreiber introduce The Open Artificial Knowledge (OAK) dataset that addresses the challenges of artificial data generation by providing a large-scale resource of over 500 million tokens. OAK utilizes an ensemble of state-of-the-art LLMs, including GPT4o, LLaMa3-70B, LLaMa3-8B, Mixtral-8x7B, Gemma-7B, and Gemma-2-9B, to generate high-quality text across diverse domains. The data generation pipeline begins by querying knowledge databases to gather topics, which are then expanded using LLMs. These topics are transformed into prompts used to generate texts with advanced models. The OAK dataset is continuously evaluated and updated to ensure its effectiveness and reliability for training advanced language models. By systematically addressing each challenge, OAK provides a robust resource for developing more accurate and aligned language models.

The OAK dataset generation follows a structured approach designed to address key challenges in artificial data creation. The process involves four main steps: subject extraction, subtopic expansion, prompt generation, and text generation with open-source LLMs. This approach tackles challenges such as diversity and generalization, quality, bias, and factual accuracy. The dataset also addresses privacy concerns by using only publicly available data and open-source models.
To ensure ethical and legal compliance, the OAK team implements a comprehensive strategy, including code publication for transparency and a commitment to content removal upon request. Toxicity and harmful content are mitigated through automated filtering techniques and fine-tuned models. The dataset’s effectiveness is evaluated using common benchmarks, and regular updates are planned to maintain relevance.
The OAK dataset has two main techniques for prompt generation: programming prompt engineering and meta prompt engineering. These methods ensure diversity in prompts while maintaining quality and addressing potential biases. The resulting dataset provides a robust resource for developing more accurate and aligned language models, with its use intended primarily for research purposes in areas such as model alignment, bias mitigation, and prompt engineering.
OAK dataset offers a comprehensive resource for AI research, derived from Wikipedia’s main categories. Utilizing advanced models like GPT4o, LLaMa3, Mixtral, Gemma, and Gemma2, OAK addresses data scarcity, privacy concerns, and diversity issues. With over 500 million tokens, this freely available dataset supports model alignment, fine-tuning, and benchmarking across various AI tasks and applications. OAK’s creation process involves sophisticated techniques to ensure quality, diversity, and ethical considerations, making it a valuable resource for advancing AI technologies while addressing critical challenges in the field of artificial data generation and utilization.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.










