FBI-LLM (Fully BInarized Large Language Model): An AI Framework Using Autoregressive Distillation for 1-bit Weight Binarization of LLMs from Scratch
Transformer-based LLMs like ChatGPT and LLaMA excel in tasks requiring domain expertise and complex reasoning due to their large parameter sizes and extensive training data. However, their substantial computational and storage demands limit broader applications. Quantization addresses these challenges by converting 32-bit parameters to smaller bit sizes, enhancing storage efficiency and computational speed. Extreme quantization, or binarization, maximizes efficiency but reduces accuracy. While strategies like retaining key parameters or near-one-bit representation offer improvements, they still need help with issues like knowledge loss, ample training data, and limited flexibility in adapting to different parameter scales and vocabularies.
Researchers from Mohamed bin Zayed University of AI and Carnegie Mellon University introduce Fully Binarized Large Language Models (FBI-LLM), training large-scale binary language models from scratch to match the performance of full-precision counterparts. Using autoregressive distillation (AD) loss, they maintain equivalent model dimensions and training data, achieving competitive perplexity and task-specific results. Their training procedure distills from a full-precision teacher, allowing stable training from random initializations. Empirical evaluations on models ranging from 130M to 7B parameters demonstrate minimal performance gaps compared to full-precision models, highlighting the potential for specialized hardware and new computational frameworks.
Neural network binarization converts model parameters to a 1-bit format, significantly improving efficiency and reducing storage, but often at the cost of accuracy. Techniques like BinaryConnect and Binarized Neural Networks (BNN) use stochastic methods and clipping functions to train binary models. Further advancements like XNOR-Net and DoReFa-Net introduce scaling factors and strategies to minimize quantization errors. In large language models, partial binarization methods like PB-LLM and BiLLM maintain key parameters at full precision, while BitNet b1.58 uses a set of {-1, 0, 1} for parameters. Recent approaches like BitNet and OneBit employ quantization-aware training for better performance.
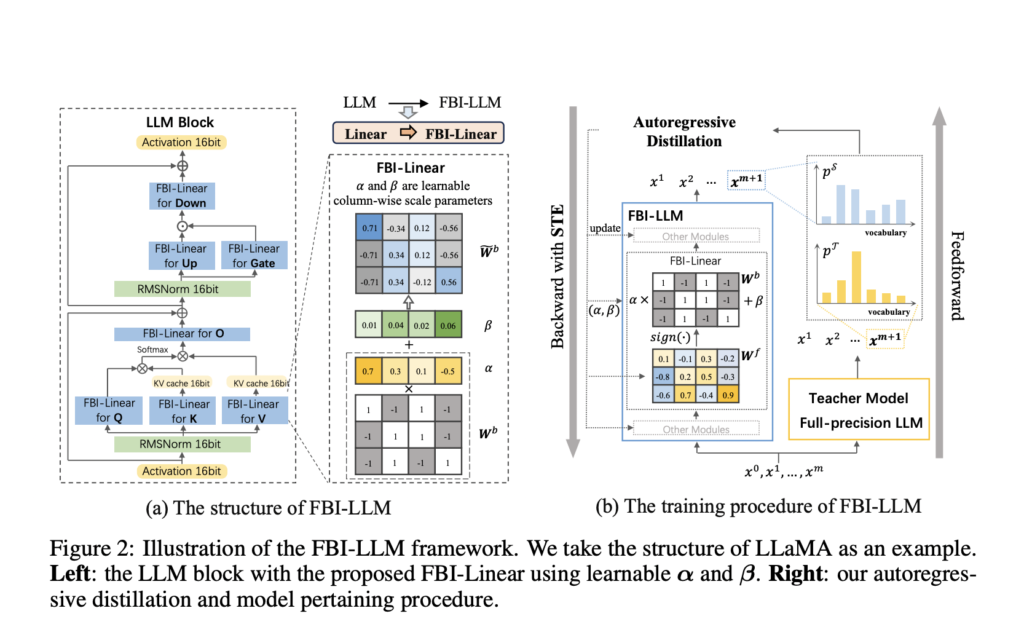
FBI-LLM modifies transformer-based LLMs by replacing all linear modules, except the causal head, with FBI-linear and keeping embedding and layer norm modules at full precision to maintain semantic information and activation scaling. FBI-linear binarizes full-precision parameters using the sign function and applies full-precision scaling factors to columns, initialized based on column averages, to reduce errors and maintain performance. For training, FBI-LLM employs autoregressive distillation, using a full-precision teacher model to guide a binarized student model via cross-entropy loss between their outputs. The Straight-Through Estimator (STE) enables gradient propagation through the non-differentiable sign function, ensuring effective optimization.

In the experiments, the researchers implemented the FBI-LLM methodology following a W1A16 configuration, which quantizes model parameters to 1-bit while retaining activation values at 16-bit precision. They trained FBI-LLMs of varying sizes—130M, 1.3B, and 7B—using the Amber dataset, a large corpus comprising 1.26 trillion tokens from diverse sources. The training utilized an Adam optimizer with specific settings and employed autoregressive distillation with LLaMA2-7B as the teacher model. Evaluation across tasks like BoolQ, PIQA, and Winogrande showed FBI-LLMs achieving competitive zero-shot accuracy and perplexity metrics, surpassing comparable binarized and full-precision models in several instances. Storage efficiency analysis demonstrated substantial compression benefits compared to full-precision LLMs, while generation tests illustrated FBI-LLMs’ capacity for fluent and informed content creation across different prompts.
The proposed framework employs autoregressive distillation to achieve a 1-bit weight binarization of LLMs from scratch. Experimental results across different model sizes—130M, 1.3B, and 7B—demonstrate that FBI-LLM surpasses existing benchmarks while effectively balancing model size and performance. However, there are notable limitations. Binarization unavoidably leads to performance degradation compared to full-precision models, and the distillation process adds computational overhead. Current hardware constraints also hinder direct speed improvements from binarized LLMs. Furthermore, ethical concerns surrounding pretrained LLMs, including biases, privacy risks, and misinformation, persist even after binarization.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.