FlashAttention-3 Released: Achieves Unprecedented Speed and Precision with Advanced Hardware Utilization and Low-Precision Computing
FlashAttention-3, the latest release in the FlashAttention series, has been designed to address the inherent bottlenecks of the attention layer in Transformer architectures. These bottlenecks are crucial for the performance of large language models (LLMs) and applications requiring long-context processing.
The FlashAttention series, including its predecessors FlashAttention and FlashAttention-2, has revolutionized how attention mechanisms operate on GPUs by minimizing memory reads and writes. Most libraries have widely adopted this innovation to accelerate Transformer training and inference, significantly contributing to the dramatic increase in LLM context length in recent years. For instance, the context length has grown from 2-4K tokens in models like GPT-3 to 128K tokens in GPT-4 and even up to 1 million tokens in models such as Llama 3.
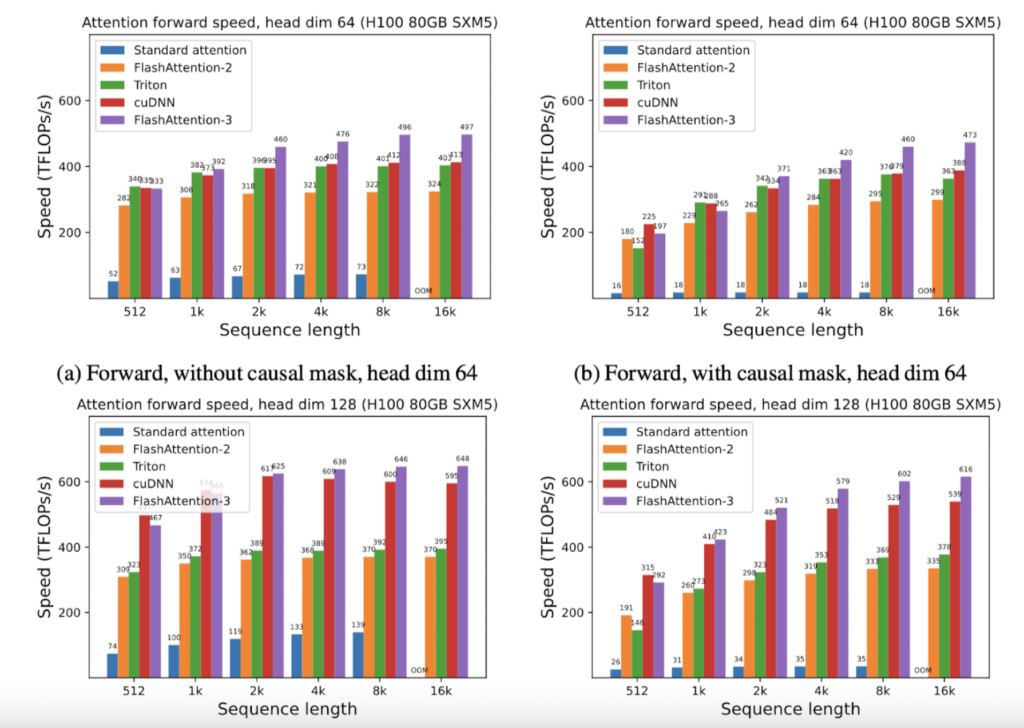
Despite these advancements, FlashAttention-2 could only achieve 35% utilization of the theoretical maximum FLOPs on the H100 GPU, highlighting a gap between potential and actual performance. FlashAttention-3 seeks to bridge this gap by leveraging new hardware capabilities in modern GPUs. Specifically, it introduces three main techniques to enhance attention speed on Hopper GPUs: exploiting the asynchrony of Tensor Cores and TMA to overlap computation and data movement, interleaving block-wise matrix multiplication and softmax operations, and utilizing incoherent processing to leverage hardware support for FP8 low-precision computations.
One of the standout features of FlashAttention-3 is its ability to exploit the asynchrony of Tensor Cores and TMA. This allows for overlapping the overall computation and data movement through warp specialization and interleaving operations. Warp specialization involves separate producer and consumer warps managing TMA and WGMMA operations. FlashAttention-3 employs inter-warpgroup and intra-warpgroup overlapping of GEMM (general matrix multiply) and softmax operations. This pingpong scheduling technique ensures that while one warpgroup performs GEMM operations, another can handle softmax calculations, thus optimizing the utilization of GPU resources.

FlashAttention-3 significantly uses low-precision FP8 computations, which double the Tensor Core throughput compared to FP16. This innovation increases computational speed and accuracy by reducing quantization error through incoherent processing. By applying the Hadamard transform with random signs to spread outliers, FlashAttention-3 effectively reduces quantization error, making it a robust solution for high-performance LLMs.
FlashAttention-3 is 1.5 to 2 times faster than FlashAttention-2 with FP16, reaching up to 740 TFLOPS, 75% of the theoretical maximum FLOPs on H100 GPUs. With FP8, FlashAttention-3 achieves close to 1.2 PFLOPS, a significant leap in performance with 2.6 times smaller error compared to baseline FP8 attention.
These advancements are underpinned by utilizing NVIDIA’s CUTLASS library, which provides powerful abstractions that allow FlashAttention-3 to harness Hopper GPUs’ capabilities. By rewriting FlashAttention to incorporate these new features, Dao AI Lab has unlocked substantial efficiency gains, enabling new model capabilities such as extended context lengths and improved inference speeds.
In conclusion, the release of FlashAttention-3 represents a paradigm shift in designing and implementing attention mechanisms in large language models. Dao AI Lab has demonstrated how targeted optimizations can lead to significant performance enhancements by closely aligning algorithmic innovations with hardware advancements. As the field continues to evolve, such breakthroughs will be crucial in pushing what is possible with large language models and their applications in various domains.
Check out the Blog, Paper, and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.