InternLM2.5-7B-Chat: Open Sourcing Large Language Models with Unmatched Reasoning, Long-Context Handling, and Enhanced Tool Use
InternLM has unveiled its latest advancement in open large language models, the InternLM2.5-7B-Chat, available in GGUF format. This model is compatible with llama.cpp, an open-source framework for LLM inference, can be utilized locally and in the cloud across various hardware platforms. The GGUF format offers half-precision and low-bit quantized versions, including q5_0, q5_k_m, q6_k, and q8_0.
InternLM2.5 builds on its predecessor, offering a 7 billion parameter base model and a chat model tailored for practical scenarios. This model boasts state-of-the-art reasoning capabilities, especially in mathematical reasoning, surpassing competitors like Llama3 and Gemma2-9B. It also features an impressive 1M context window, demonstrating near-perfect performance in long-context tasks such as those assessed by LongBench.
The model’s ability to handle long contexts makes it particularly effective in retrieving information from extensive documents. This capability is enhanced when paired with LMDeploy, a toolkit developed by the MMRazor and MMDeploy teams for compressing, deploying, and serving LLMs. The InternLM2.5-7B-Chat-1M variant, designed for 1M-long context inference, exemplifies this strength. This version requires significant computational resources, such as 4xA100-80G GPUs, to operate effectively.
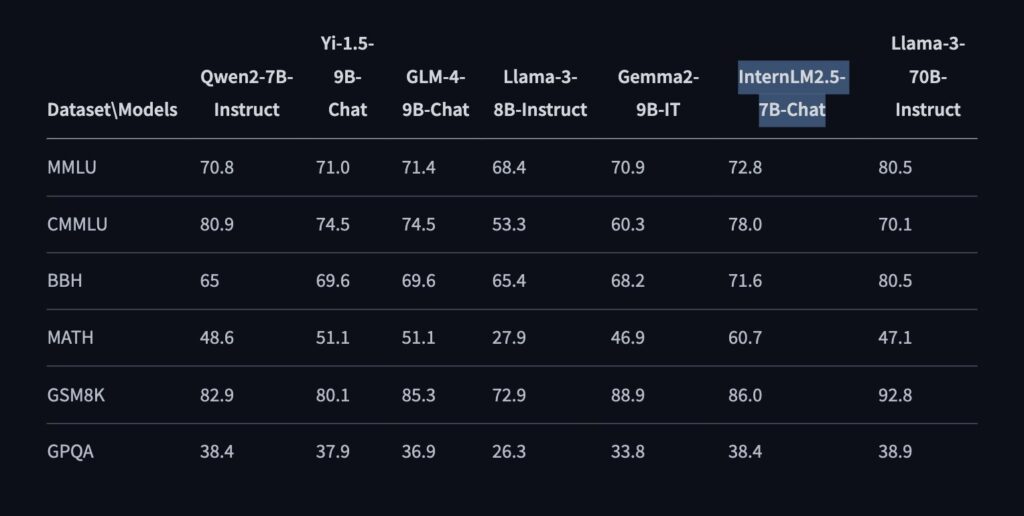
Performance evaluations conducted using the OpenCompass tool highlight the model’s competencies across various dimensions: disciplinary competence, language competence, knowledge competence, inference competence, and comprehension competence. In benchmarks like MMLU, CMMLU, BBH, MATH, GSM8K, and GPQA, InternLM2.5-7B-Chat consistently delivers superior performance compared to its peers. For instance, the MMLU benchmark achieves a score of 72.8, outpacing models like Llama-3-8B-Instruct and Gemma2-9B-IT.

InternLM2.5-7B-Chat also excels at handling tool use, supporting gathering information from over 100 web pages. The upcoming release of Lagent will further enhance this functionality, improving the model’s capabilities in instruction following, tool selection, and reflection.
The model’s release includes a comprehensive installation guide, model download instructions, and model inference and service deployment examples. Users can perform batched offline inference with the quantized model using lmdeploy, a framework supporting INT4 weight-only quantization and deployment (W4A16). This setup offers up to 2.4x faster inference than FP16 on compatible NVIDIA GPUs, including the 20, 30, and 40 series and A10, A16, A30, and A100.
InternLM2.5’s architecture retains the robust features of its predecessor while incorporating new technical innovations. These enhancements, driven by a large corpus of synthetic data and an iterative training process, result in a model with improved reasoning performance—boasting a 20% increase over InternLM2. This iteration also maintains the capability to handle 1M context windows with near-full accuracy, making it a leading model for long-context tasks.
In conclusion, with the release of InternLM2.5 and its variants with its advanced reasoning capabilities, long-context handling, and efficient tool use, InternLM2.5-7B-Chat is set to be a valuable resource for various applications in both research and practical scenarios.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.