LongRAG: A New Artificial Intelligence AI Framework that Combines RAG with Long-Context LLMs to Enhance Performance
Retrieval-Augmented Generation (RAG) methods enhance the capabilities of large language models (LLMs) by incorporating external knowledge retrieved from vast corpora. This approach is particularly beneficial for open-domain question answering, where detailed and accurate responses are crucial. By leveraging external information, RAG systems can overcome the limitations of relying solely on the parametric knowledge embedded in LLMs, making them more effective in handling complex queries.
A significant challenge in RAG systems is the imbalance between the retriever and reader components. Traditional frameworks often use short retrieval units, such as 100-word passages, requiring the retriever to sift through large amounts of data. This design burdens the retriever heavily while the reader’s task remains relatively simple, leading to inefficiencies and potential semantic incompleteness due to document truncation. This imbalance restricts the overall performance of RAG systems, necessitating a re-evaluation of their design.
Current methods in RAG systems include techniques like Dense Passage Retrieval (DPR), which focuses on finding precise, short retrieval units from large corpora. These methods often involve recalling many units and employing complex re-ranking processes to achieve high accuracy. While effective to some extent, these approaches still need to work on inherent inefficiency and incomplete semantic representation due to their reliance on short retrieval units.
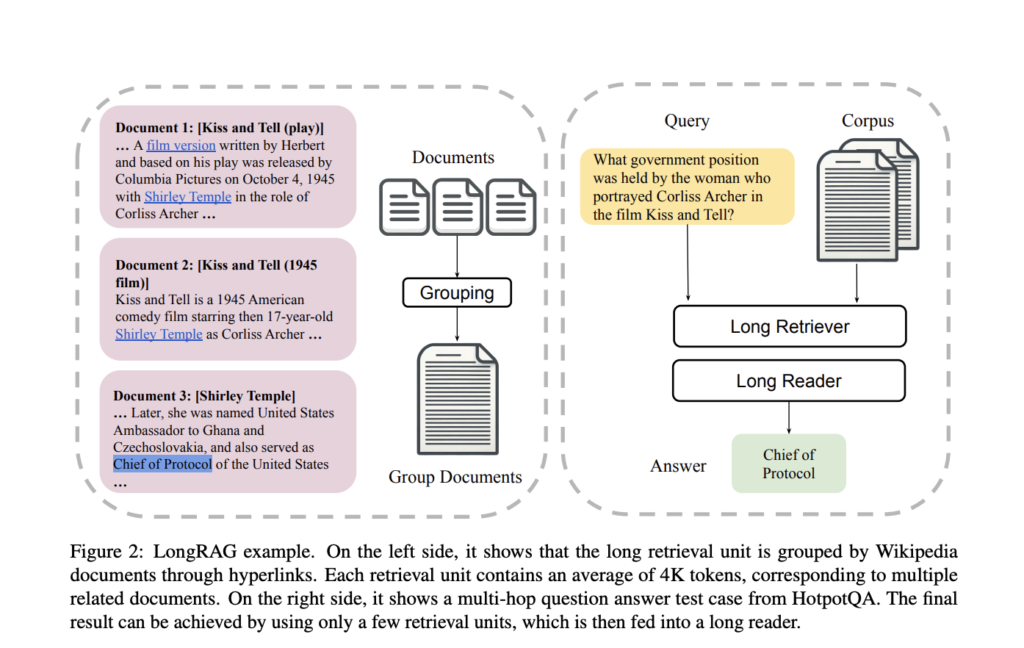
To address these challenges, the research team from the University of Waterloo introduced a novel framework called LongRAG. This framework comprises a “long retriever” and a “long reader” component, designed to process longer retrieval units of around 4K tokens each. By increasing the size of the retrieval units, LongRAG reduces the number of units from 22 million to 600,000, significantly easing the retriever’s workload and improving retrieval scores. This innovative approach allows the retriever to handle more comprehensive information units, enhancing the system’s efficiency and accuracy.

The LongRAG framework operates by grouping related documents into long retrieval units, which the long retriever then processes to identify relevant information. To extract the final answers, the retriever filters the top 4 to 8 units, concatenated and fed into a long-context LLM, such as Gemini-1.5-Pro or GPT-4o. This method leverages the advanced capabilities of long-context models to process large amounts of text efficiently, ensuring a thorough and accurate extraction of information.
In-depth, the methodology involves using an encoder to map the input question to a vector and a different encoder to map the retrieval units to vectors. The similarity between the question and the retrieval units is calculated to identify the most relevant units. The long retriever searches through these units, reducing the corpus size and improving the retriever’s precision. The retrieved units are then concatenated and fed into the long reader, which uses the context to generate the final answer. This approach ensures that the reader processes a comprehensive set of information, improving the system’s overall performance.
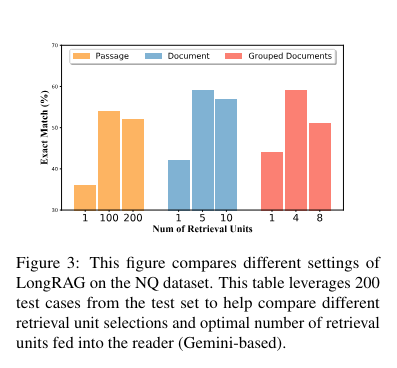
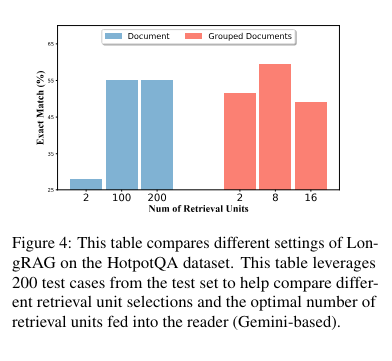
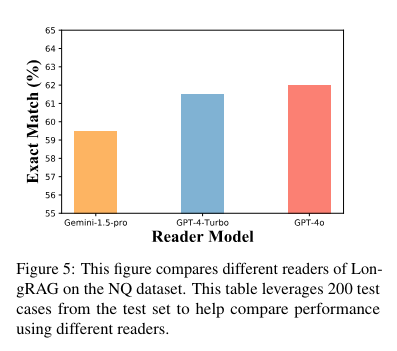
The performance of LongRAG is truly remarkable. On the Natural Questions (NQ) dataset, it achieved an exact match (EM) score of 62.7%, a significant leap forward compared to traditional methods. On the HotpotQA dataset, it reached an EM score of 64.3%. These impressive results demonstrate the effectiveness of LongRAG, matching the performance of state-of-the-art fine-tuned RAG models. The framework reduced the corpus size by 30 times and improved the answer recall by approximately 20 percentage points compared to traditional methods, with an answer recall@1 score of 71% on NQ and 72% on HotpotQA.
LongRAG’s ability to process long retrieval units preserves the semantic integrity of documents, allowing for more accurate and comprehensive responses. By reducing the burden on the retriever and leveraging advanced long-context LLMs, LongRAG offers a more balanced and efficient approach to retrieval-augmented generation. The research from the University of Waterloo not only provides valuable insights into modernizing RAG system design but also highlights the exciting potential for further advancements in this field, sparking optimism for the future of retrieval-augmented generation systems.
In conclusion, LongRAG represents a significant step forward in addressing the inefficiencies and imbalances in traditional RAG systems. Employing long retrieval units and leveraging the capabilities of advanced LLMs’ capabilities enhances the accuracy and efficiency of open-domain question-answering tasks. This innovative framework improves retrieval performance and sets the stage for future developments in retrieval-augmented generation systems.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
🚀 Create, edit, and augment tabular data with the first compound AI system, Gretel Navigator, now generally available! [Advertisement]
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.