Anthropic’s Claude 3.5 Sonnet beats GPT-4o in most benchmarks

Anthropic has launched Claude 3.5 Sonnet, its mid-tier model that outperforms competitors and even surpasses Anthropic’s current top-tier Claude 3 Opus in various evaluations.
Claude 3.5 Sonnet is now accessible for free on Claude.ai and the Claude iOS app, with higher rate limits for Claude Pro and Team plan subscribers. It’s also available through the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. The model is priced at $3 per million input tokens and $15 per million output tokens, featuring a 200K token context window.
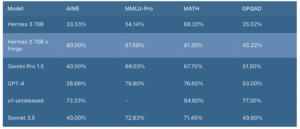
Anthropic claims that Claude 3.5 Sonnet “sets new industry benchmarks for graduate-level reasoning (GPQA), undergraduate-level knowledge (MMLU), and coding proficiency (HumanEval).” The model demonstrates enhanced capabilities in understanding nuance, humour, and complex instructions, while excelling at producing high-quality content with a natural tone.
Operating at twice the speed of Claude 3 Opus, Claude 3.5 Sonnet is well-suited for complex tasks such as context-sensitive customer support and multi-step workflow orchestration. In an internal agentic coding evaluation, it solved 64% of problems, significantly outperforming Claude 3 Opus at 38%.

The model also showcases improved vision capabilities, surpassing Claude 3 Opus on standard vision benchmarks. This advancement is particularly noticeable in tasks requiring visual reasoning, such as interpreting charts and graphs. Claude 3.5 Sonnet can accurately transcribe text from imperfect images, a valuable feature for industries like retail, logistics, and financial services.
Alongside the model launch, Anthropic introduced Artifacts on Claude.ai, a new feature that enhances user interaction with the AI. This feature allows users to view, edit, and build upon Claude’s generated content in real-time, creating a more collaborative work environment.
Despite its significant intelligence leap, Claude 3.5 Sonnet maintains Anthropic’s commitment to safety and privacy. The company states, “Our models are subjected to rigorous testing and have been trained to reduce misuse.”
External experts, including the UK’s AI Safety Institute (UK AISI) and child safety experts at Thorn, have been involved in testing and refining the model’s safety mechanisms.
Anthropic emphasises its dedication to user privacy, stating, “We do not train our generative models on user-submitted data unless a user gives us explicit permission to do so. To date we have not used any customer or user-submitted data to train our generative models.”
Looking ahead, Anthropic plans to release Claude 3.5 Haiku and Claude 3.5 Opus later this year to complete the Claude 3.5 model family. The company is also developing new modalities and features to support more business use cases, including integrations with enterprise applications and a memory feature for more personalised user experiences.
(Image Credit: Anthropic)
See also: OpenAI co-founder Ilya Sutskever’s new startup aims for ‘safe superintelligence’

Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.