
NYU Researchers Propose Inter- & Intra-Modality Modeling (I2M2) for Multi-Modal Learning, Capturing both Inter-Modality and Intra-Modality Dependencies
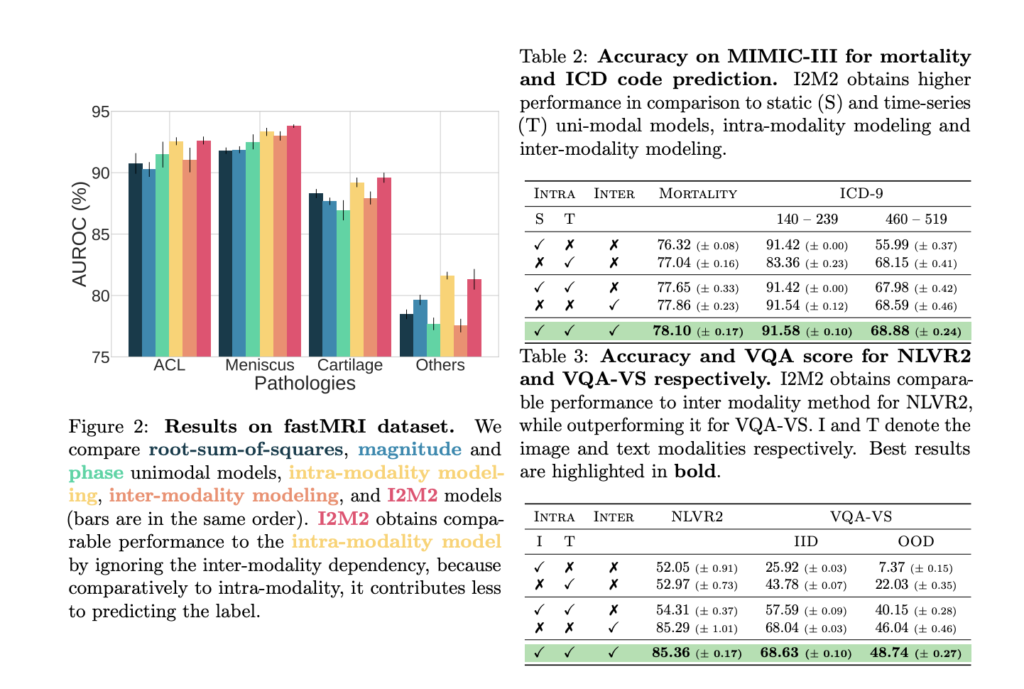
In supervised multi-modal learning, data is mapped from various modalities to a target label using information about the boundaries between the modalities. Different fields have been interested in this issue: autonomous vehicles, healthcare, robots, and many more. Although multi-modal learning is a fundamental paradigm in machine learning, its efficacy differs depending on the task at hand. In some situations, a multi-modal learner performs better than a uni-modal learner. Still, in other cases, it might not be better than a single uni-modal learner or a mixture of only two. These conflicting findings highlight the need for a guiding framework to clarify the reasons behind the performance gaps between multi-modal models and to lay out a standard procedure for developing models that better use multi-modal data.
Researchers from New York University, Genentech, and CIFAR are embarking on a groundbreaking journey to resolve these inconsistencies. They are introducing a novel, more principled approach to multi-modal learning, one that has never been explored before, and by identifying the underlying variables that cause them. Using a unique probabilistic perspective, they propose a mechanism that generates data and examines the supervised multi-modal learning problem.
Since this selection variable produces the interdependence between the modalities and the label, it is always set to one. This selection mechanism’s efficacy differs throughout datasets. Dependencies between modalities and labels, known as inter-modality dependencies, are amplified in cases of strong selection effects. In contrast, when the selection impact is modest, intra-modality dependencies—dependencies between individual modalities and the label—become increasingly important.
The proposed paradigm assumes that labels are the primary source of modalities-specific data. It further specifies the connection between the label, the selection process, and the various modalities. From one use case to the next, the amount to which the output relies on data from different modalities and the relationships between them varies. A multi-modal system has to simulate the inter- and intra-modality dependencies because it’s important to know how strong these dependencies are regarding the ultimate goal. The team accomplished this by developing and merging classifiers for each modality to capture the dependencies within each modality and a classifier to capture the dependencies between the output label and the interactions across different modes.

The I2M2 method is derived from the multi-modal generative model, a widely used approach in multi-modal learning. However, the prior research on multi-modal learning can be divided into two groups using the suggested framework. The methods of inter-modal modeling, which are grouped in the first group, rely heavily on detecting inter-modal relationships to predict the target. Despite their theoretical capability to capture connections between and within modalities, they often fail in practice due to unfulfilled assumptions about the multi-modal learning-generating model. The methods used in intra-modality modeling, which fall under the second group, rely solely on labels for interactions between modalities, limiting their effectiveness.
In contradiction to the goal of multi-modal learning, these methods fail to grasp the interdependence of the modalities for prediction. When predicting the label, inter-modality methods work well when modalities exchange substantial information, but intra-modality methods work well when cross-modality information is scarce or nonexistent.
Because it is not necessary to know in advance how strong these dependencies are, the suggested I2M2 architecture overcomes this drawback. Because it explicitly describes interdependence across and within modalities, it can adapt to different contexts and still be effective. The results demonstrate that I2M2 is not just superior, but a game-changer, to both intra- and inter-modality approaches by validating researcher’s claims on various datasets. Automatic diagnosis utilizing knee MRI scans and mortality and ICD-9 code prediction in the MIMIC-III dataset are two examples of the many healthcare jobs to which this technology is applied. Findings on vision-and-language tasks like NLVR2 and VQA further prove the transformative potential of I2M2.
Dependencies differ in strength between datasets, as our comprehensive evaluation indicates; the fastMRI dataset benefits more from intra-modality dependencies, whereas the NLVR2 dataset finds more relevance in inter-modality dependencies. The AV-MNIST, MIMIC-III, and VQA datasets are affected by both dependencies. In every respect, I2M2 succeeds, guaranteeing solid performance independent of the relative importance of its dependencies. This thorough research and its robust findings instill confidence in the effectiveness of I2M2.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.









