
Alibaba AI Research Releases CosyVoice 2: An Improved Streaming Speech Synthesis Model
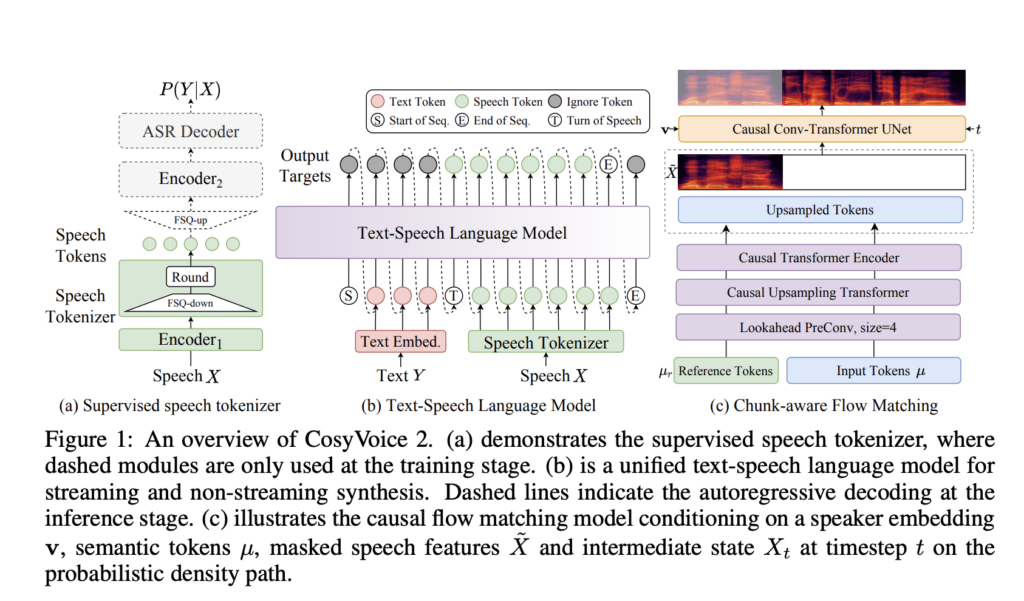
Speech synthesis technology has made notable strides, yet challenges remain in delivering real-time, natural-sounding audio. Common obstacles include latency, pronunciation accuracy, and speaker consistency—issues that become critical in streaming applications where responsiveness is paramount. Additionally, handling complex linguistic inputs, such as tongue twisters or polyphonic words, often exceeds the capabilities of existing models. To address these issues, researchers at Alibaba have unveiled CosyVoice 2, an enhanced streaming TTS model designed to resolve these challenges effectively.
Introducing CosyVoice 2
CosyVoice 2 builds upon the foundation of the original CosyVoice, bringing significant upgrades to speech synthesis technology. This enhanced model focuses on refining both streaming and offline applications, incorporating features that improve flexibility and precision across diverse use cases, including text-to-speech and interactive voice systems.
Key advancements in CosyVoice 2 include:
Unified Streaming and Non-Streaming Modes: Seamlessly adaptable to various applications without compromising performance.

Enhanced Pronunciation Accuracy: A reduction of pronunciation errors by 30%-50%, improving clarity in complex linguistic scenarios.
Improved Speaker Consistency: Ensures stable voice output across zero-shot and cross-lingual synthesis tasks.
Advanced Instruction Capabilities: Offers precise control over tone, style, and accent through natural language instructions.

Innovations and Benefits
CosyVoice 2 integrates several technological advancements to enhance its performance and usability:
Finite Scalar Quantization (FSQ): Replacing traditional vector quantization, FSQ optimizes the use of the speech token codebook, improving semantic representation and synthesis quality.
Simplified Text-Speech Architecture: Leveraging pre-trained large language models (LLMs) as its backbone, CosyVoice 2 eliminates the need for additional text encoders, streamlining the model while boosting cross-lingual performance.
Chunk-Aware Causal Flow Matching: This innovation aligns semantic and acoustic features with minimal latency, making the model suitable for real-time speech generation.
Expanded Instructional Dataset: With over 1,500 hours of training data, the model enables granular control over accents, emotions, and speech styles, allowing for versatile and expressive voice generation.
Performance Insights
Extensive evaluations of CosyVoice 2 underscore its strengths:
Low Latency and Efficiency: Response times as low as 150ms make it well-suited for real-time applications like voice chat.
Improved Pronunciation: The model achieves significant enhancements in handling rare and complex linguistic constructs.
Consistent Speaker Fidelity: High speaker similarity scores demonstrate the ability to maintain naturalness and consistency.
Multilingual Capability: Strong results on Japanese and Korean benchmarks highlight its robustness, though challenges remain with overlapping character sets.
Resilience in Challenging Scenarios: CosyVoice 2 excels in difficult cases such as tongue twisters, outperforming previous models in accuracy and clarity.


Conclusion
CosyVoice 2 thoughtfully advances from its predecessor, addressing key limitations in latency, accuracy, and speaker consistency with scalable solutions. The integration of advanced features like FSQ and chunk-aware flow matching offers a balanced approach to performance and usability. While opportunities remain to expand language support and refine complex scenarios, CosyVoice 2 lays a strong foundation for the future of speech synthesis. Bridging offline and streaming modes ensures high-quality, real-time audio generation for diverse applications.
Check out the Paper, Hugging Face Page, Pre-Trained Model, and Demo. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.









