
Decoding the Hidden Computational Dynamics: A Novel Machine Learning Framework for Understanding Large Language Model Representations
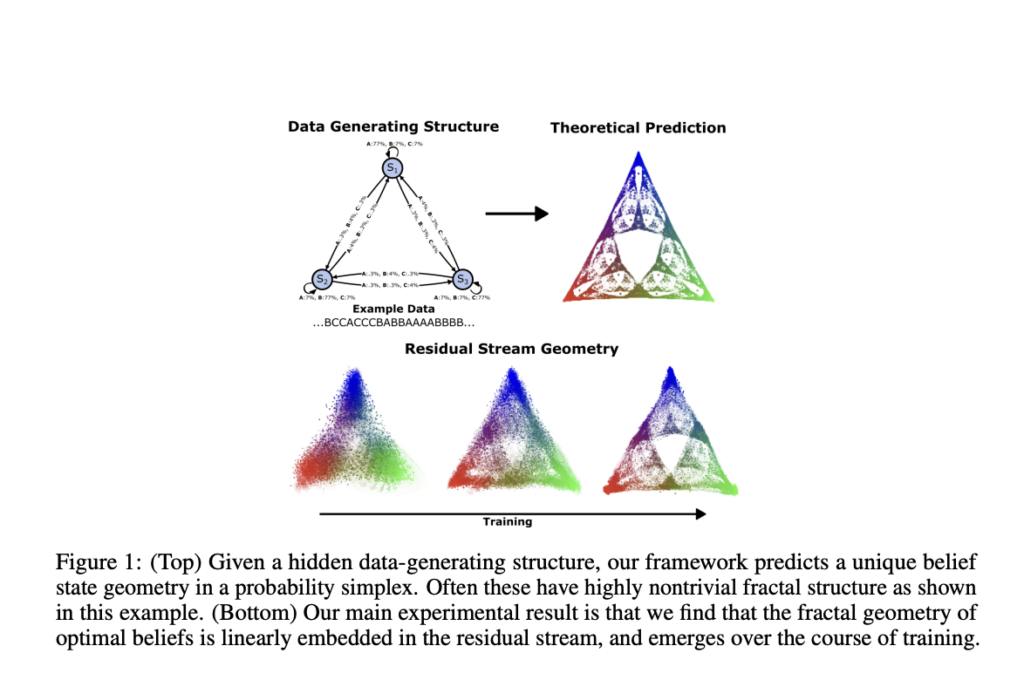
In the rapidly evolving landscape of machine learning and artificial intelligence, understanding the fundamental representations within transformer models has emerged as a critical research challenge. Researchers are grappling with competing interpretations of what transformers represent—whether they function as statistical mimics, world models, or something more complex. The core intuition suggests that transformers might capture the hidden structural dynamics of data-generation processes, enabling complex next-token prediction. This perspective was notably articulated by prominent AI researchers who argue that accurate token prediction implies a deeper understanding of underlying generative realities. However, traditional methods lack a robust framework for analyzing these computational representations.
Existing research has explored various aspects of transformer models’ internal representations and computational limitations. The “Future Lens” framework revealed that transformer hidden states contain information about multiple future tokens, suggesting a belief-state-like representation. Researchers have also investigated transformer representations in sequential games like Othello, interpreting these representations as potential “world models” of game states. Empirical studies have shown transformers’ algorithmic task limitations in graph path-finding and hidden Markov models (HMMs). Moreover, Bayesian predictive models have attempted to provide insights into state machine representations, drawing connections to the mixed-state presentation approach in computational mechanics.
Researchers from PIBBSS, Pitzer and Scripps College, and University College London, Timaeus have proposed a novel approach to understanding the computational structure of large language models (LLMs) during next-token prediction. Their research focuses on uncovering the meta-dynamics of belief updating over hidden states of data-generating processes. It is found that belief states are linearly represented in transformer residual streams with the help of optimal prediction theory, even when the predicted belief state geometry shows complex fractal structures. Moreover, the study explores how these belief states are represented in the final residual stream or distributed across multiple layer streams.
The proposed methodology uses a detailed experimental approach to analyze transformer models trained on HMM-generated data. Researchers focus on examining the residual stream activations across different layers and context window positions, creating a comprehensive dataset of activation vectors. For each input sequence, the framework determines the corresponding belief state and its associated probability distribution over hidden states of the generative process. The researchers utilize linear regression to establish an affine mapping between residual stream activations and belief state probabilities. This mapping is achieved by minimizing the mean squared error between predicted and true belief states, resulting in a weight matrix that projects residual stream representations onto the probability simplex.

The research yielded significant insights into the computational structure of transformers. Linear regression analysis reveals a two-dimensional subspace within 64-dimensional residual activations that closely matches the predicted fractal structure of belief states. This finding provides compelling evidence that transformers trained on data with hidden generative structures learn to represent belief state geometries in their residual stream. The empirical results demonstrated varying correlations between belief state geometry and next-token predictions across different processes. For the RRXOR process, belief state geometry showed a strong correlation (R² = 0.95), significantly outperforming next-token prediction correlations (R² = 0.31).
In conclusion, researchers present a theoretical framework to establish a direct connection between training data structure and the geometric properties of transformer neural network activations. By validating the linear representation of belief state geometry within the residual stream, the study reveals that transformers develop predictive representations far more complex than simple next-token prediction. The research offers a promising pathway toward enhanced model interpretability, trustworthiness, and potential improvements by concretizing the relationship between computational structures and training data. It also bridges the critical gap between the advanced behavioral capabilities of LLMs and the fundamental understanding of their internal representational dynamics.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.









