01.AI Introduces Yi-1.5-34B Model: An Upgraded Version of Yi with a High-Quality Corpus of 500B Tokens and Fine-Tuned on 3M Diverse Fine-Tuning Samples
The recent Yi-1.5-34B model introduced by 01.AI has brought about yet another advancement in the field of Artificial Intelligence. Positioned as a major improvement over its predecessors, this unique model bridges the gap between Llama 3 8B and 70B. It promises better performance in a number of areas, such as multimodal capability, code production, and logical reasoning. The complexities of the Yi-1.5-34B model, its creation, and its possible effects on the AI community have been explored in depth by the team of researchers.
The Yi-34B model served as the basis for the Yi-1.5-34B model’s development. The Yi-1.5-34B carries on the tradition of Yi-34B, which was recognized for its superior performance and functioned as an unofficial benchmark in the AI community. This is due to its improved training and optimization. The model’s intense training regimen has been demonstrated by the fact that it was pre-trained on an incredible 500 billion tokens, earning 4.1 trillion tokens in total.
Yi-1.5-34B’s architecture is intended to be a well-balanced combination, providing the computational efficiency of Llama 3 8B-sized models and getting close to the broad capabilities of 70B-sized models. This equilibrium guarantees that the model can carry out intricate tasks without necessitating the enormous computational resources that are generally linked with large-scale models.
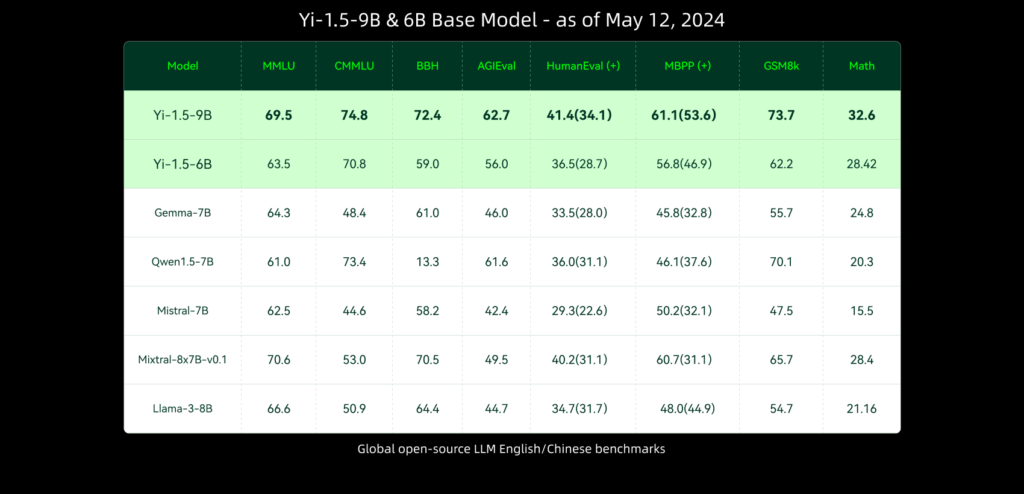
When compared against benchmarks, the Yi-1.5-34B model has shown remarkable performance. Its large vocabulary helps it solve logical puzzles with ease and grasp complex ideas in a subtle way. Its capacity to produce code snippets longer than those generated by GPT-4 is one of its most notable properties, demonstrating its usefulness in actual applications. The model’s speed and efficiency have been commended by users who have tested it through demos, making it an appealing option for a variety of AI-driven activities.

The Yi family encompasses multimodal and language models, going beyond text to include vision-language features. This is accomplished by aligning visual representations within the language model’s semantic space by combining a vision transformer encoder with the chat language model. Also, the Yi models are not limited to conventional settings. With lightweight ongoing pretraining, they have been extended to handle long contexts of up to 200,000 tokens.
One of the main reasons for the Yi models’ effectiveness is the careful data engineering procedure that has been used in their creation. The models used 3.1 trillion tokens from Chinese and English corpora for pretraining. To ensure the best quality inputs, this data was carefully selected utilizing a cascaded deduplication and quality filtering pipeline.
The process of fine-tuning enhanced the model’s capabilities even further. Machine learning engineers iteratively refined and validated a small-scale instruction dataset with less than 10,000 instances. Thanks to this practical approach to data verification, the performance of the refined models is guaranteed to be precise and dependable.
With its combination of excellent performance and usefulness, the Yi-1.5-34B model is a great development in Artificial Intelligence. It is a flexible tool for both researchers and practitioners because of its capacity to perform complicated tasks like multimodal integration, code development, and logical reasoning.
Check out the Model Card and Demo. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.